突然想起了王牌对王牌中的传声筒:信息减弱到最后一个人一头雾水,一脸懵逼,一知半解,一心想死。

RNN的金鱼记忆
想象一个预测任务:“我出生在法国……(中间隔了100个词)……所以我说一口流利的___?”
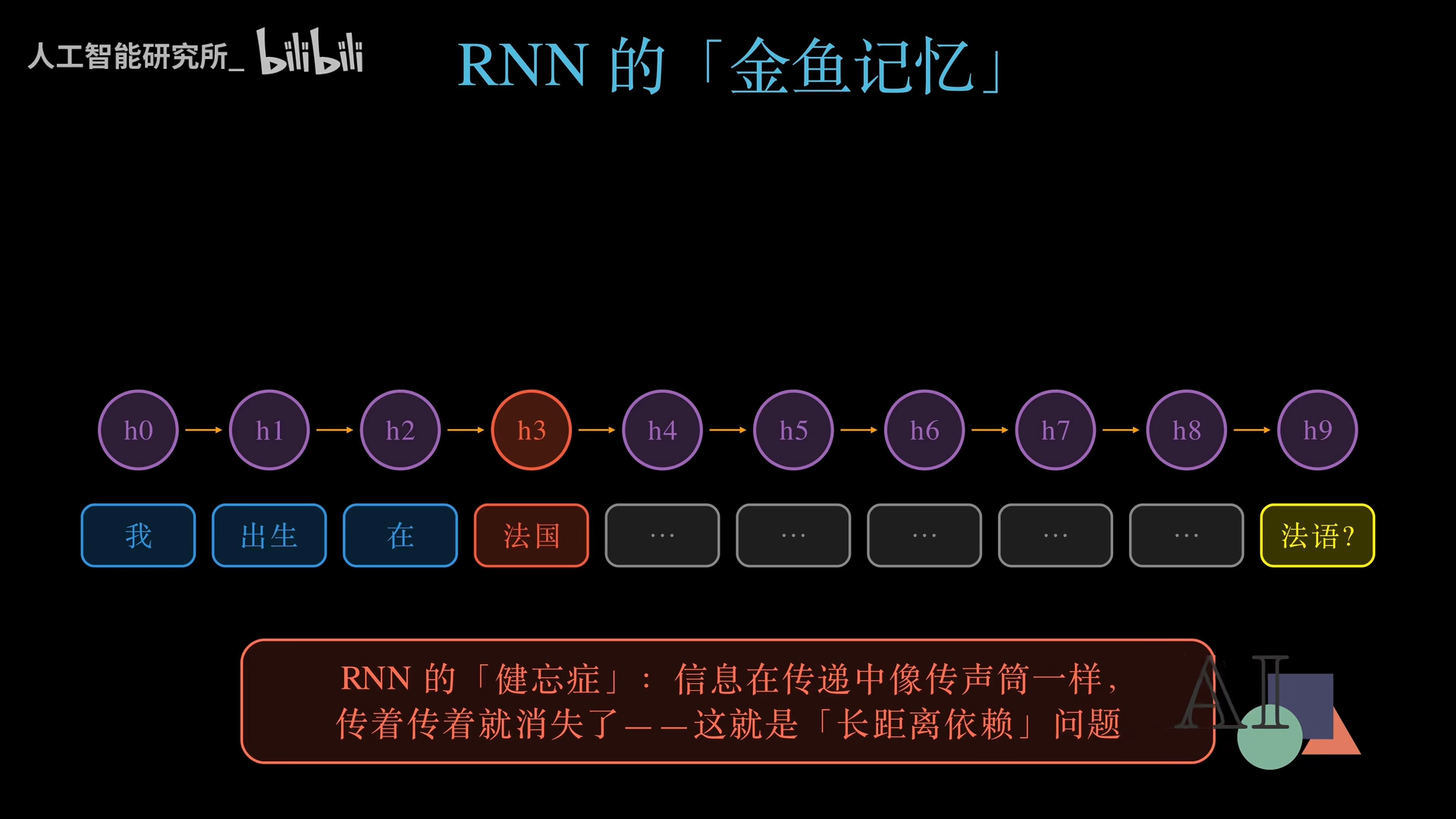
对人类来说,哪怕中间有一整段废话,我们的大脑也能轻松锁定“法国”这个关键线索,填出“法语”。但传统RNN做不到。
RNN的核心机制是按时间步展开,像一个接力的传声筒。当输入“法国”时,代表法国的记忆被短暂标记。但随着后续无关词汇不断输入,RNN需要不断更新隐藏状态,记忆逐渐淡化——颜色越来越暗,体积越来越小。等到了句尾需要预测时,悲剧发生了:RNN预测出了“英语”,它早就把“法国”忘得一干二净。
这就是AI界著名的 长距离依赖问题。在RNN架构里,信息传递距离越长,信号损失越严重。
罪魁祸首:梯度消失
要理解RNN为何健忘,需要了解 梯度消失 现象。
神经网络的学习靠反向传播。当模型在句尾预测错误时,需要把错误信号从右往左传回去,告诉前面的神经元:“你刚才没记住重点。”但每往回传一层,梯度数值就缩小一点。传到开头的“法国”时,信号衰减到几乎为零,模型完全没收到反馈。


这背后是 连乘 的数学本质。假设每传递一次乘以0.9,随着步数增加——0.9的10次方、50次方、100次方——在微积分链式法则下,小于1的数不断相乘,结果被碾压成零。
梯度消失意味着句子开头的“法国”在训练时永远得不到足够的指导去更新权重,传统RNN陷入了死局。
LSTM的解决方案:高速公路
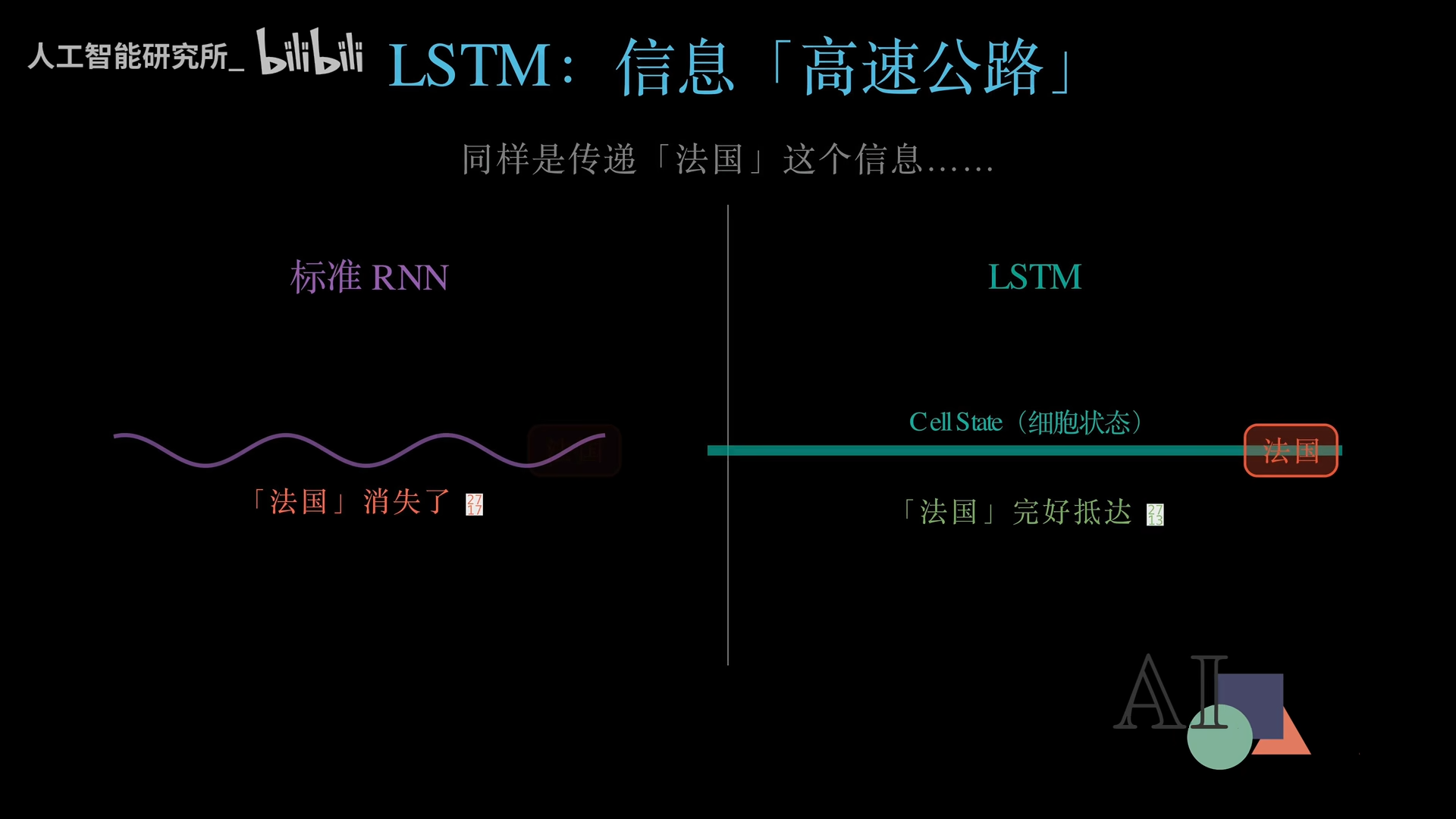
既然传统RNN得了“绝症”,科学家们决定另起炉灶,修一条全新的高速公路——这就是LSTM。它专门修了一条笔直的高速公路,名叫 细胞状态(Cell State)。
在标准RNN中,代表“法国”的信息在泥泞小路上越走越少;而在LSTM中,“法国”沿着高速公路跑完整条句子,依然是满血状态完好抵达。
这条公路能无损传递的秘密在一个核心公式里:CT = CT-1 × F + 新信息(输入门控制)。最重要的就是中间的 加号。新信息通过加法叠加到旧信息上,而不是覆盖掉旧信息。梯度有了两条路径——一条走乘法(传统RNN路径),另一条走加法(细胞状态路径)。即使乘法路径的梯度衰减了,加法路径依然能让梯度无损回流,彻底解决了梯度消失问题。
三个智能门卫
LSTM安排了三个门卫来管理信息:
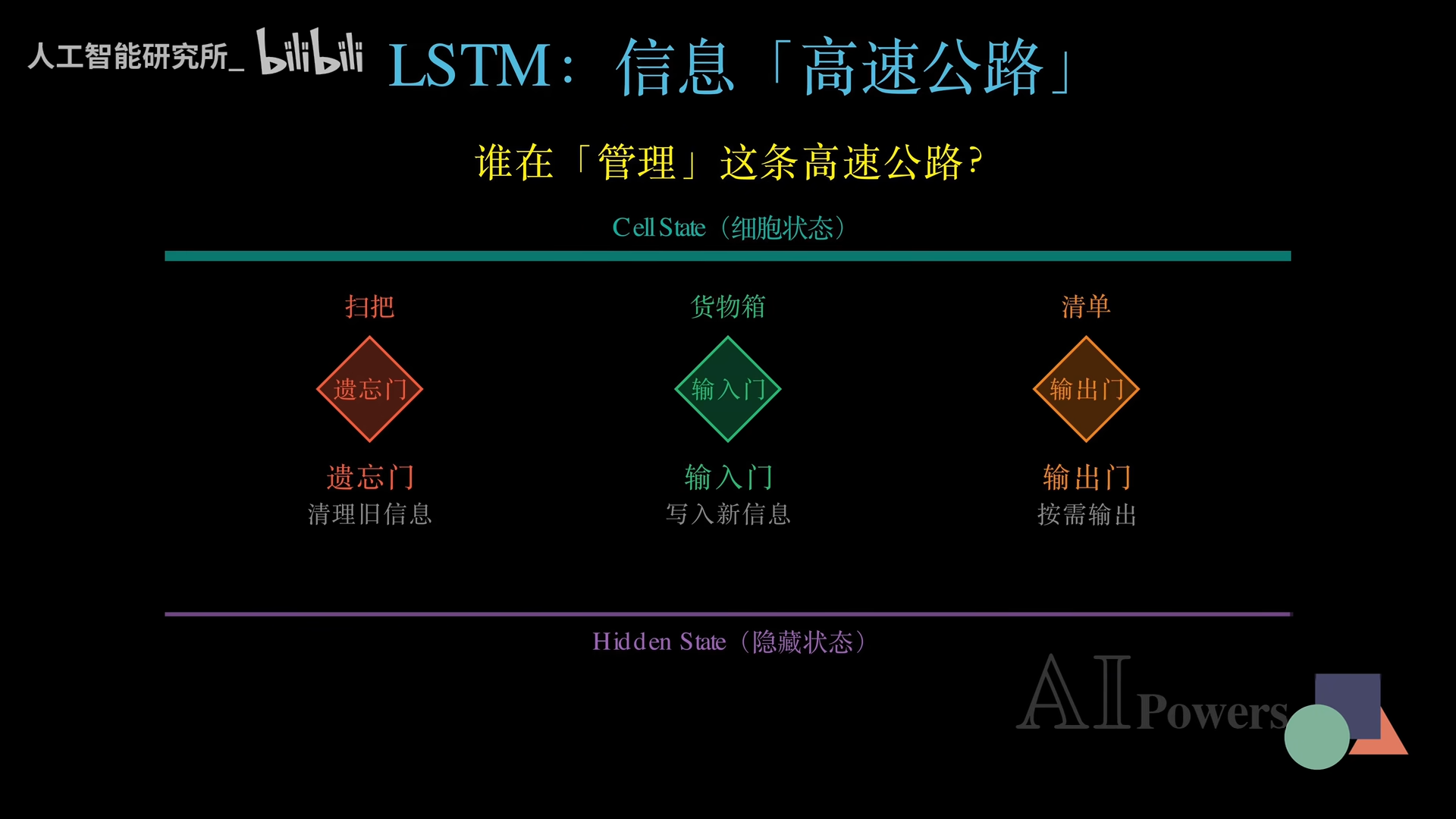
1. 遗忘门(红色):清理旧信息,决定保留多少过去的记忆。给不重要的信息输出低数值,接近0代表“全部忘记”。
2. 输入门(绿色):决定新信息的重要程度,并把核心内容提炼成候选记忆,加入细胞状态。
3. 输出门(橙色):按需提取信息。虽然记住了很多,但只输出当前任务需要的内容。
硬核公式解析
LSTM的计算公式如下(逐项解读):
| 门 | 公式 | 作用 |
|---|---|---|
| 遗忘门 | f_t = σ( W_f · [h_{t-1}, x_t] + b_f ) | 控制旧细胞状态保留比例 |
| 输入门1 | i_t = σ( W_i · [h_{t-1}, x_t] + b_i ) | 控制新信息写入比例 |
| 候选记忆 | Ĉ_t = tanh( W_c · [h_{t-1}, x_t] + b_c ) | 提炼新知识 |
| 细胞状态更新 | C_t = f_t * C_{t-1} + i_t * Ĉ_t | 核心公式:旧记忆乘遗忘门 + 新记忆乘输入门 |
| 输出门 | o_t = σ( W_o · [h_{t-1}, x_t] + b_o ) | 控制输出多少当前细胞状态 |
| 最终输出 | h_t = o_t * tanh(C_t) | 有选择地输出记忆 |
重点看细胞状态更新公式中的 加号——这是LSTM解决梯度消失的关键设计。
为什么加法能解决梯度消失

在反向传播时,RNN的梯度路径是一连串矩阵乘法,像漏水的管子,越往后流越细,最终断流。而LSTM的细胞状态路径像一条高速公路,梯度沿着加法的分支可以无损地流回很久之前的时间步。
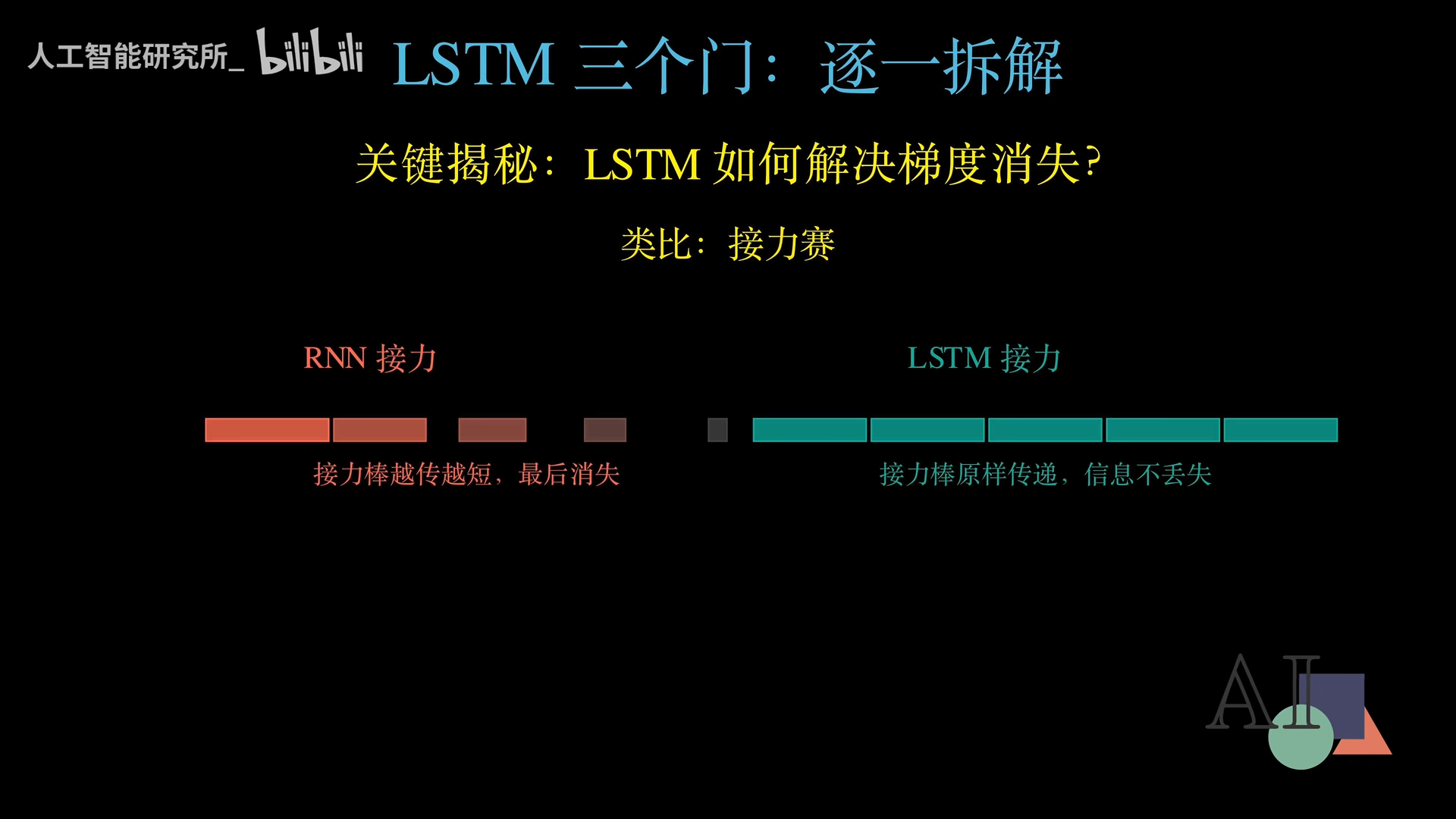
LSTM用加法连接细胞状态,让梯度有了不会断裂的生命线。
LSTM的代价
药是好药,就是太慢。三个门卫加两条状态线,意味着海量的参数和缓慢的计算速度。科学家们于是开始探索更轻量的方案——GRU(门控循环单元)。
GRU:精简版高手
GRU大幅简化了LSTM:
长距离依赖问题(梯度消失),导致早期信息在长序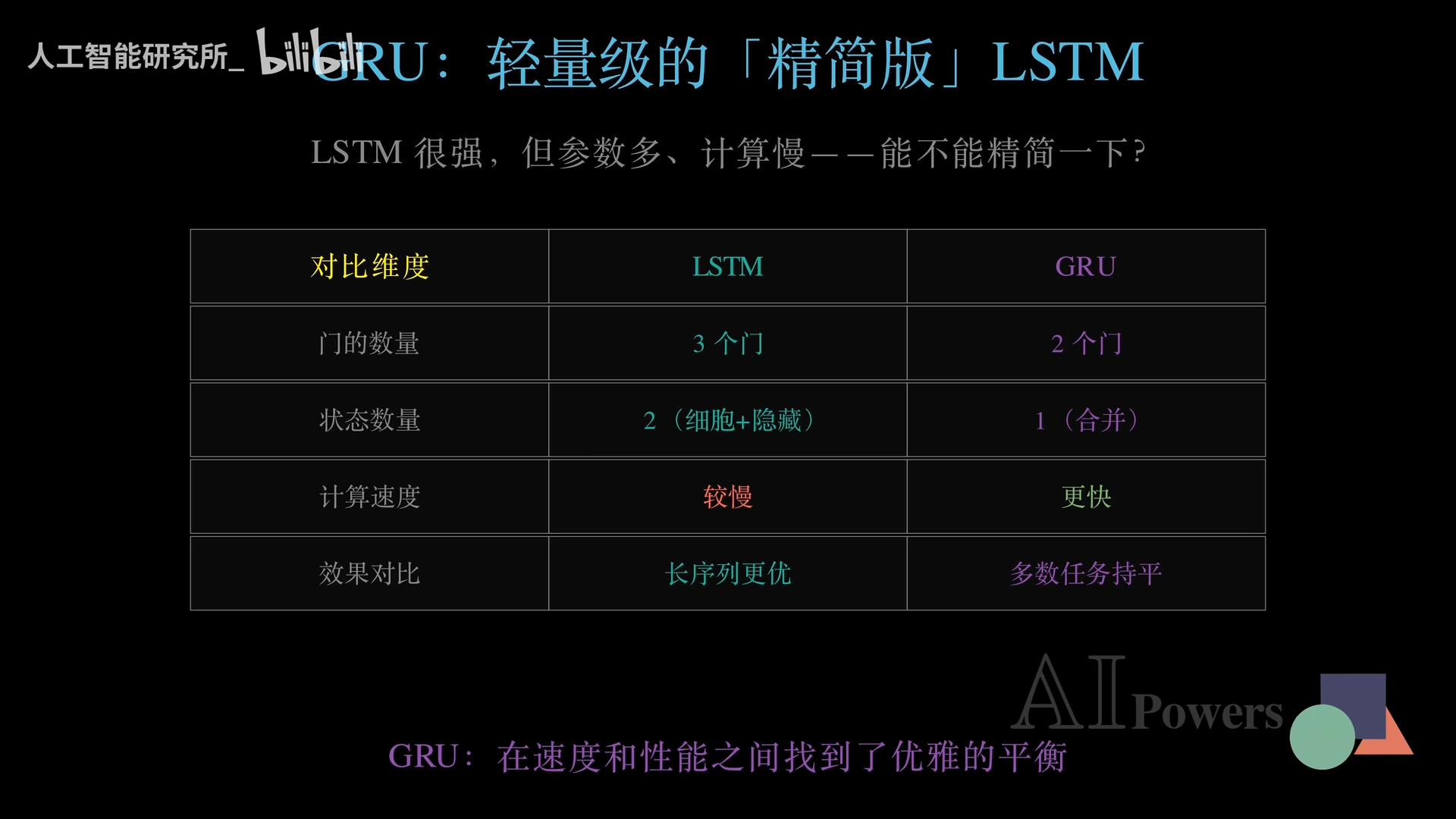 列中完全丢失。
列中完全丢失。
第一招:裁员。发现遗忘门和输入门本质上是硬币的正反面——既然决定忘记多少旧知识,就等于决定了保留多少新知识。GRU把这俩合并成一个 更新门。
第二招:合并办公区。LSTM把长期记忆和当前输出分开,GRU直接合并成一个状态,所有信息在一个状态里更新和传递。
效果:GRU砍掉了1/3的状态数量(从两个变成一个),计算速度大幅提升。在绝大部分常规任务中,GRU表现与LSTM几乎打平,但速度快得多。
三代模型大阅兵
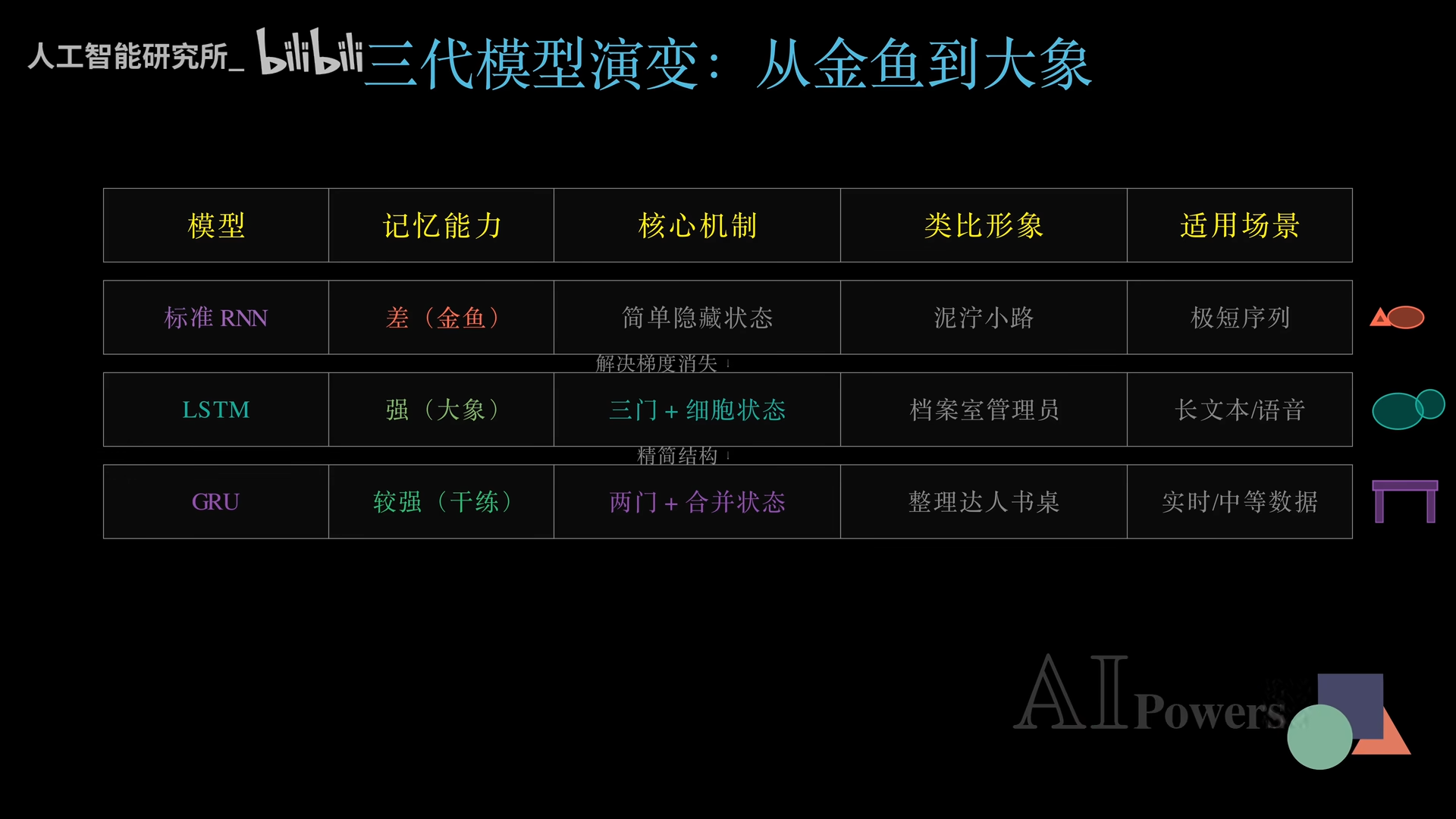
从金鱼到大象再到干练达人,每一代架构都在直击上一代的核心痛点。这就是人工智能不断向前迭代的底层逻辑。
思考题与答案
1. 标准RNN最主要的缺点是什么?
2. LSTM如何解决梯度消失?
通过细胞状态更新公式中的 加法操作,让梯度在反向传播时有一条无损通道回到早期时间步,解决了连乘导致的梯度衰减。
3. LSTM的三个门分别是什么?各有什么作用?
遗忘门(决定保留多少旧记忆)、输入门(决定加入多少新信息)、输出门(决定输出多少当前记忆)。
4. GRU相比LSTM做了哪些简化?
合并遗忘门和输入门为更新门,合并细胞状态和隐藏状态为一个状态,大幅减少参数,提升计算速度。
5. 在什么场景下GRU的性能可能不如LSTM?
在处理超长文本或需要精细记忆控制的场景下,LSTM凭借独立遗忘门和输入门仍有微弱优势。
