Flash Attention 为什么那么快?原理详解
大家好,今天我们来深入探讨一个在大型语言模型训练中几乎成为标配的技术——Flash Attention。从它的论文标题《FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness》就能看出,它具有两大核心优势:Fast(加速训练) 和 Memory Efficient(节省显存)。更重要的是,它保证了exact attention,即计算结果与标准注意力完全一致,而非像某些方法那样通过牺牲精度来换取速度。最后,“IO-Awareness”揭示了它的关键思路:通过优化输入/输出(IO)效率来提升性能。
一、标准 Attention 的计算过程与 IO 瓶颈
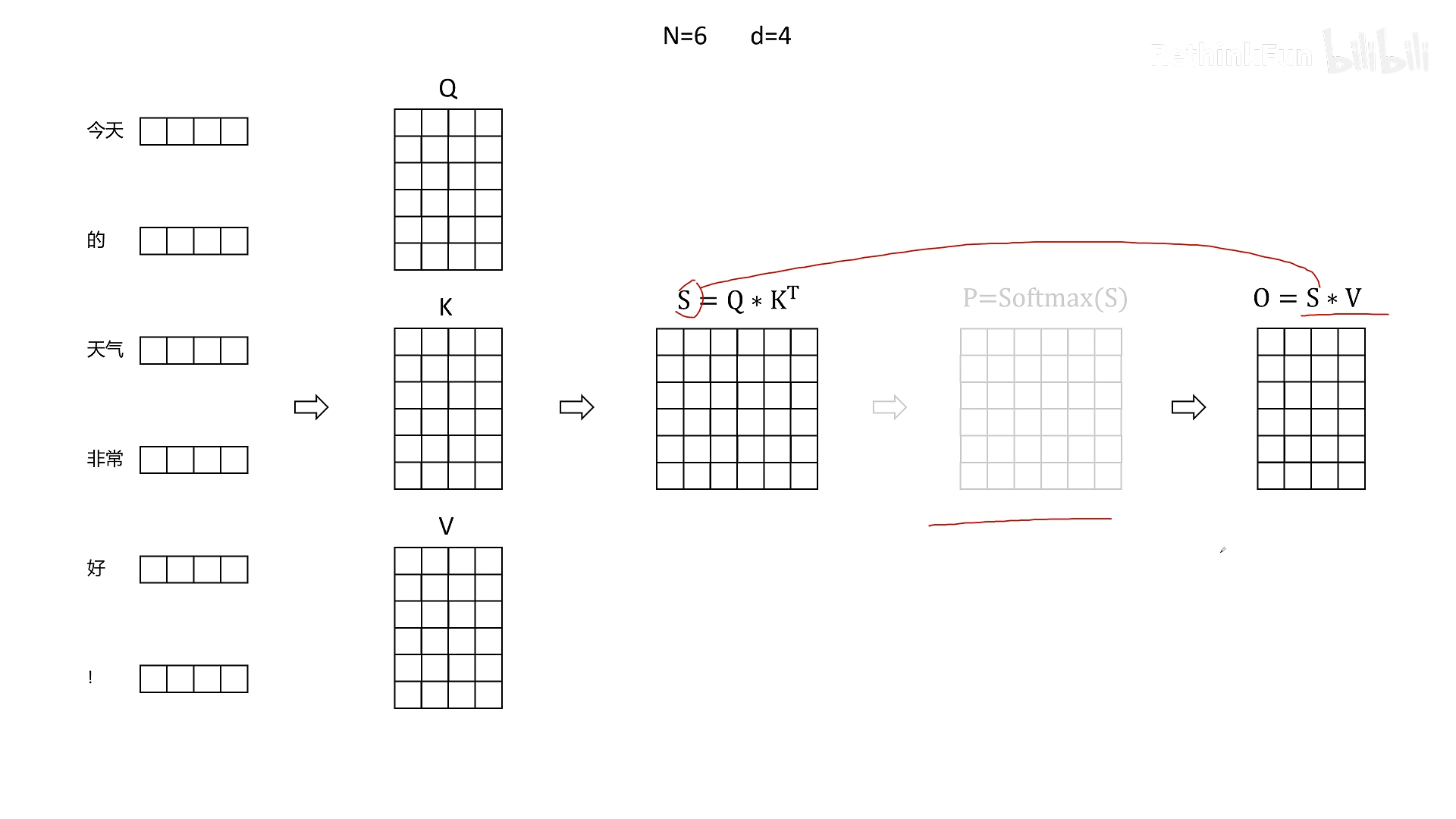
我们先回顾一下标准 Transformer 中 Attention 的计算流程。假设输入 token 经过线性变换得到 Q、K、V 矩阵,形状均为 N×D(N 为序列长度,D 为特征维度)。标准计算步骤为:
- 计算 S = Q × Kᵀ (形状 N×N)
- 对 S 按行做 Softmax,得到 P (形状 N×N)
- 计算 O = P × V (形状 N×D)
(为了简洁,此处省略了缩放因子、多头机制和 Dropout)
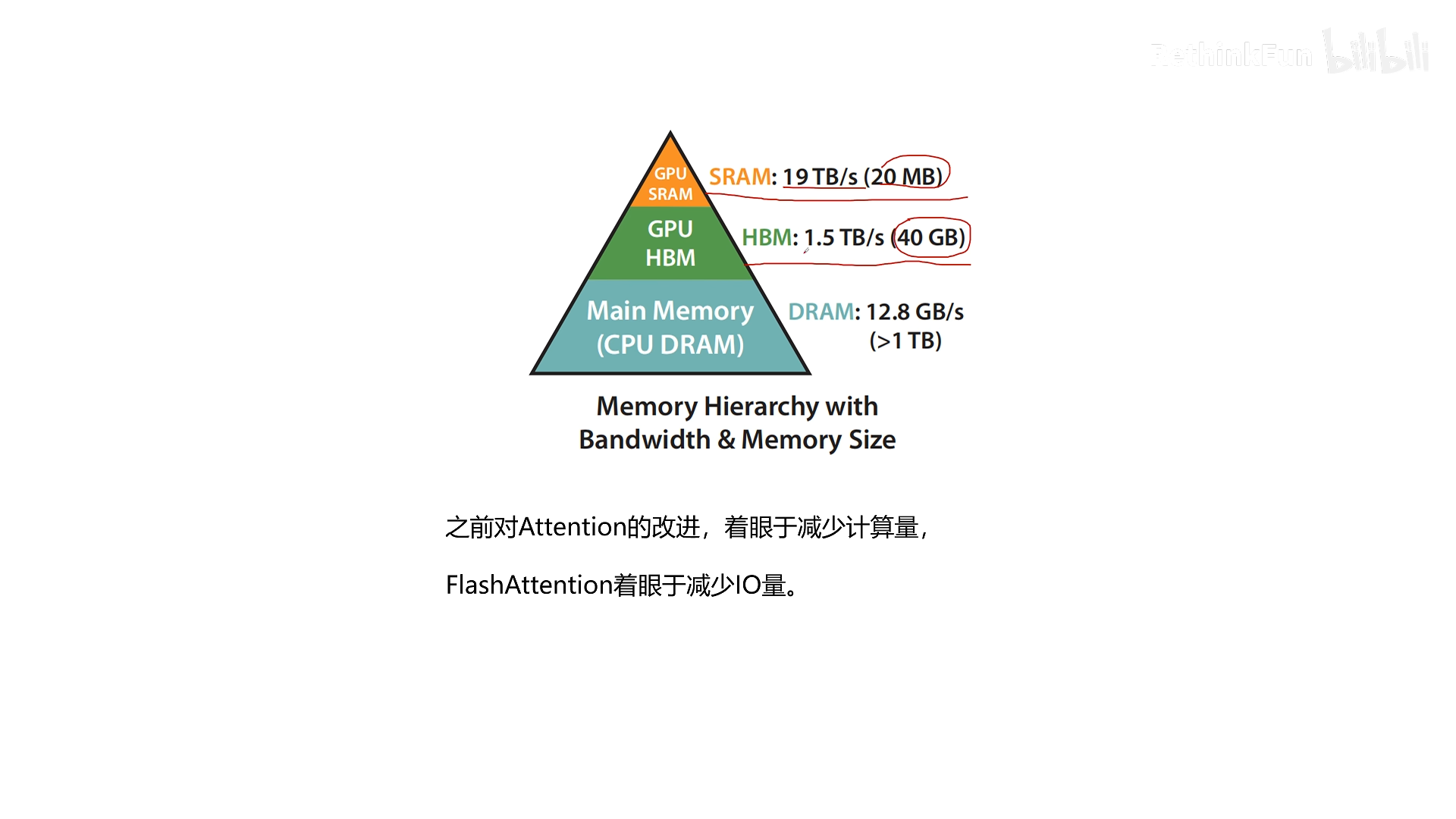
如果用 PyTorch 实现,在 GPU 上运行时,数据流动如下(存储层级:SRAM 是芯片上的高速缓存,HBM 是显存):
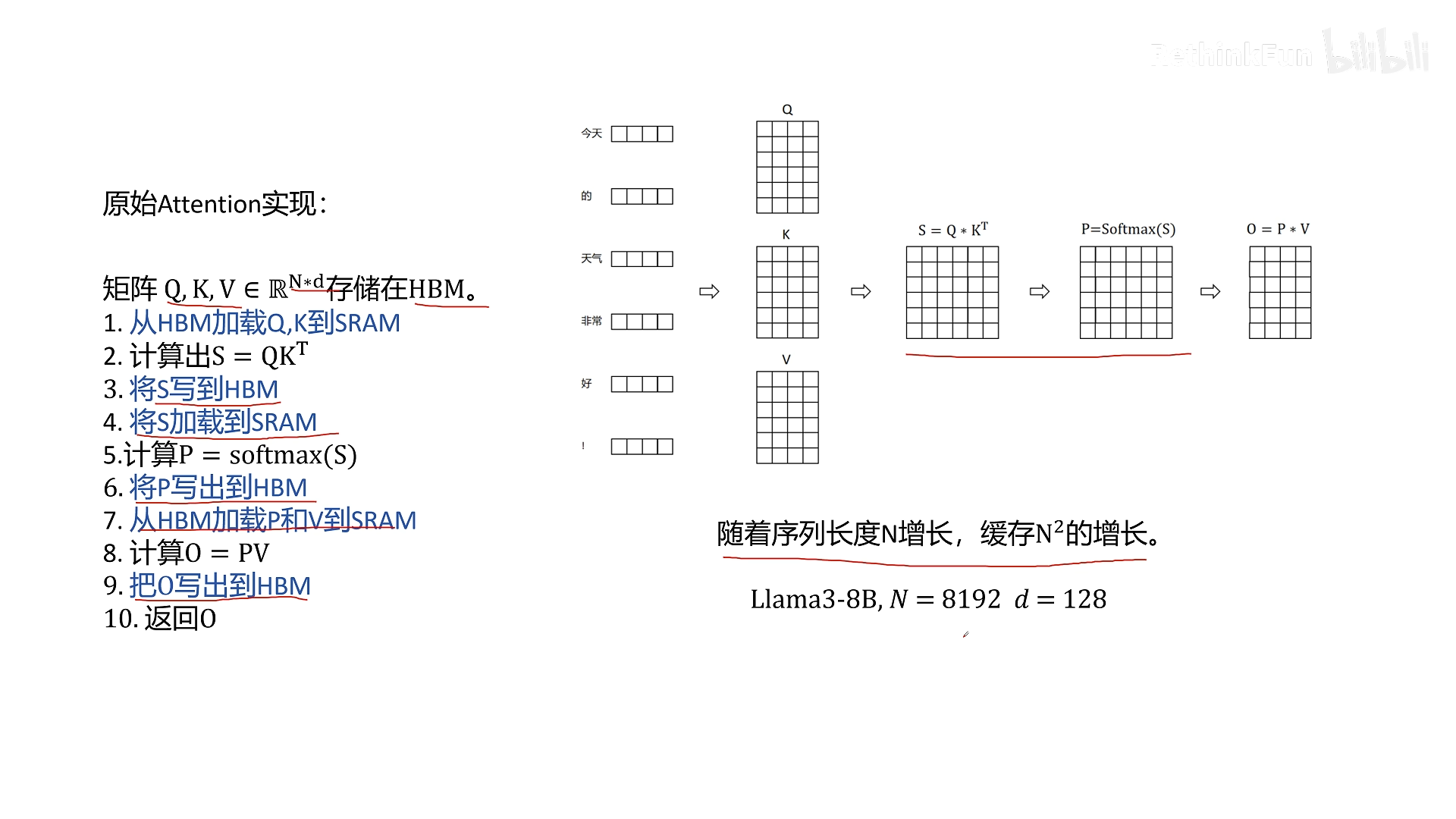
- 从 HBM 加载 Q, K 到 SRAM
- 计算 S = Q × Kᵀ
- 将 S 写回 HBM
- 从 HBM 加载 S 到 SRAM
- 计算 P = Softmax(S)
- 将 P 写回 HBM
- 从 HBM 加载 P 和 V 到 SRAM
- 计算 O = P × V
- 将 O 写回 HBM
- 返回 O
问题在哪? 中间变量 S 和 P 的大小随序列长度 N 的平方增长。例如,LLaMA-3 8B 模型支持 8192 序列长度,每个 token 维度 128,那么 S 和 P 需要占用 8192×8192×2 字节 ≈ 134MB (FP16),这还只是单层的中间结果。对于多层 Transformer 和多头注意力,显存占用会迅速膨胀。而且,这些中间结果在反向传播时是必需的(用于计算梯度),因此不能直接丢弃。
计算 vs 内存带宽
GPU 中,训练速度受限于两种情况:
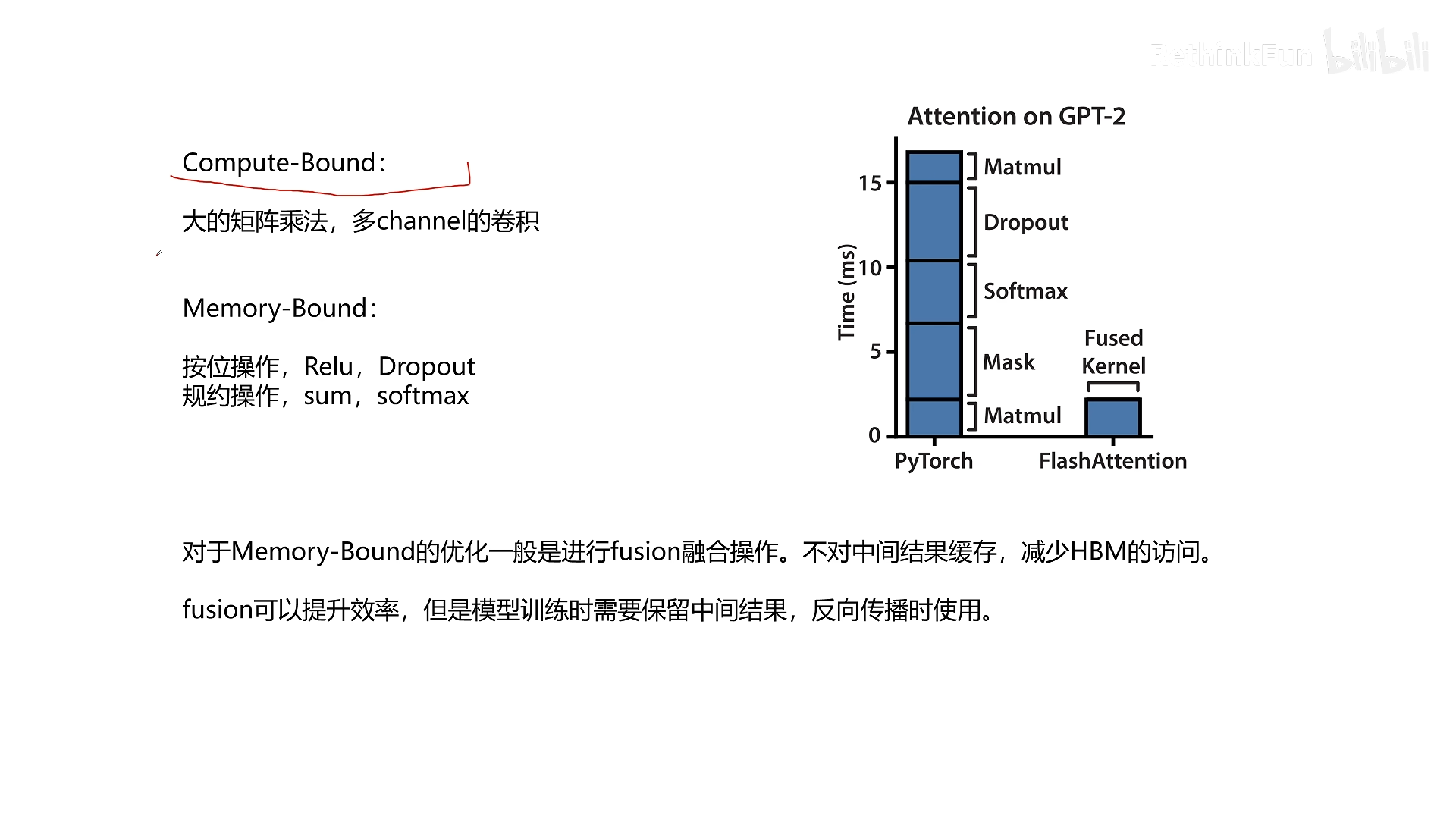
- Compute Bound:瓶颈在计算单元,如大矩阵乘法(GEMM)、多通道卷积。这类操作数据量相对不大,但计算量大,算力被充分利用。
- Memory Bound:瓶颈在数据读取速度,如逐元素操作(加法、ReLU)、规约操作(求和、Softmax)。这类操作数据量大,但计算简单,GPU 算力在等待数据从 HBM 搬运。
标准 Attention 的计算中,绝大多数操作是 Memory Bound。矩阵乘法(Compute Bound)只占很少时间,而大量的读写 HBM 操作(如存 S、读 S、存 P、读 P)占据了主要时间。因此,优化 Attention 的关键在于减少对 HBM 的访问,也就是减少 IO 开销。
二、Flash Attention 的核心思想:通过分块和融合减少 IO
Flash Attention 的解决思路是:
- 矩阵分块(Tiling):将 Q、K、V 切分成小块,每次只将必要的块加载到 SRAM 中计算。
- 算子融合(Fusion):将多个操作(Q×Kᵀ、Softmax、P×V)合并成一次计算,避免中间结果写回 HBM。
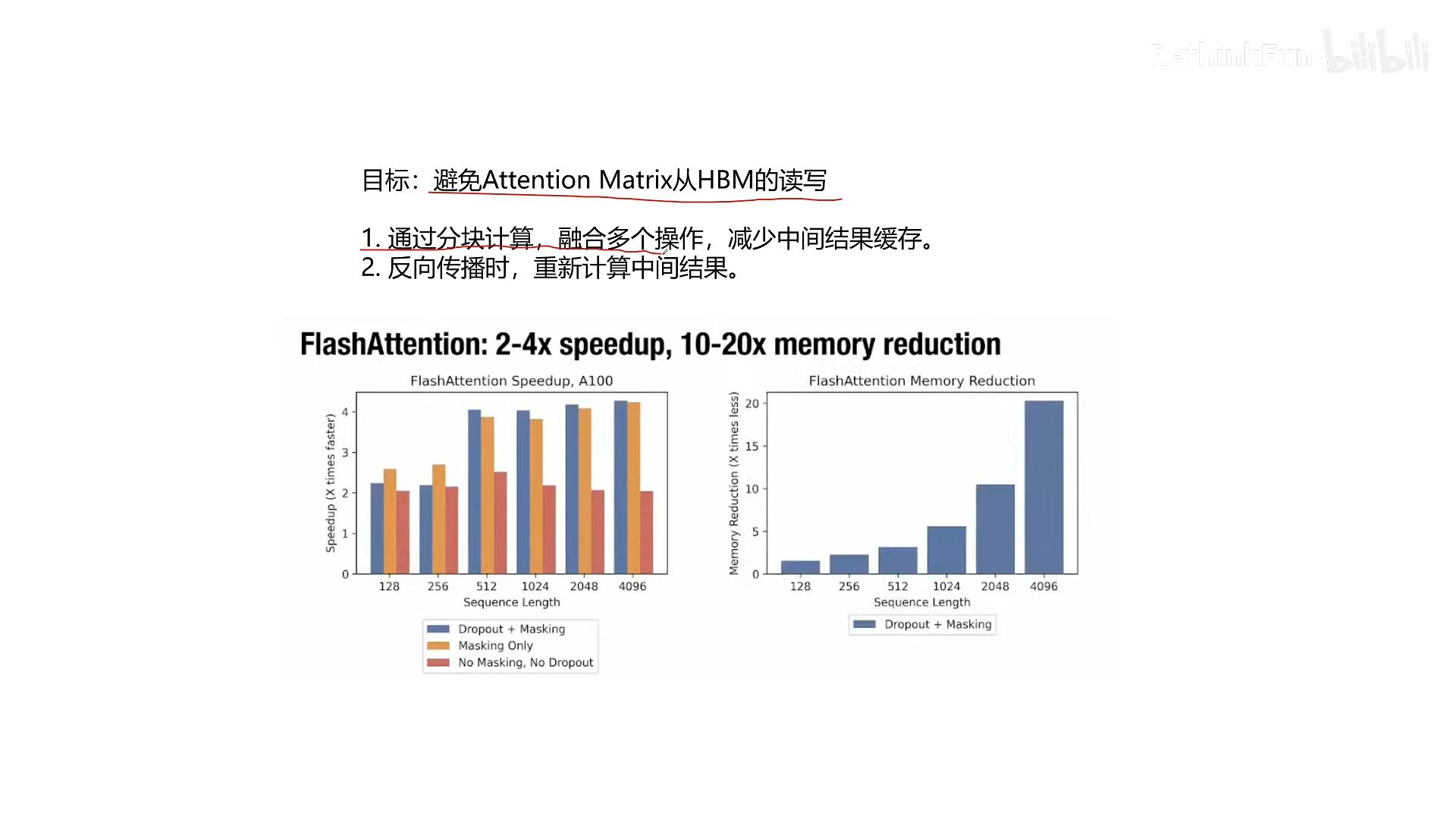
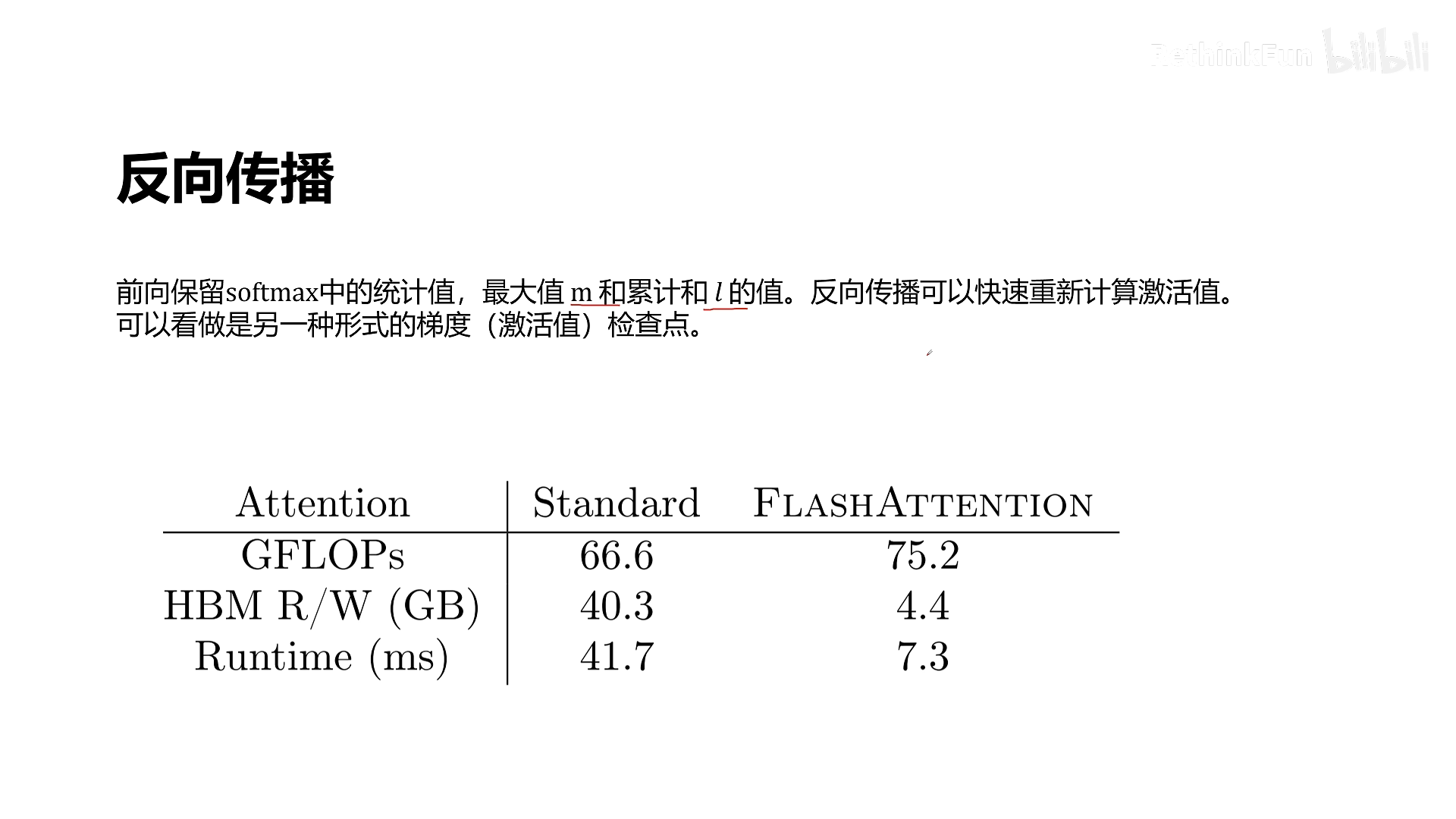
- 反向传播重计算(Recomputation):不保存 S 和 P,反向传播时利用保存的少量统计量(如最大值和指数和)重新计算它们——类似梯度检查点技术。
通过这三点,Flash Attention 实现了 2~4 倍训练速度提升,并且将显存占用从 O(N²) 降低到 O(N)。当序列长度 N=4096 时,显存占用仅为 PyTorch 标准实现的 1/20。
动画演示:分块融合计算(忽略 Softmax 的情况)
我们先假设计算的是 O = QKᵀ × V(即不考虑 Softmax,直接加权平均),以便理解分块思想。
步骤简述(如视频动画所示):
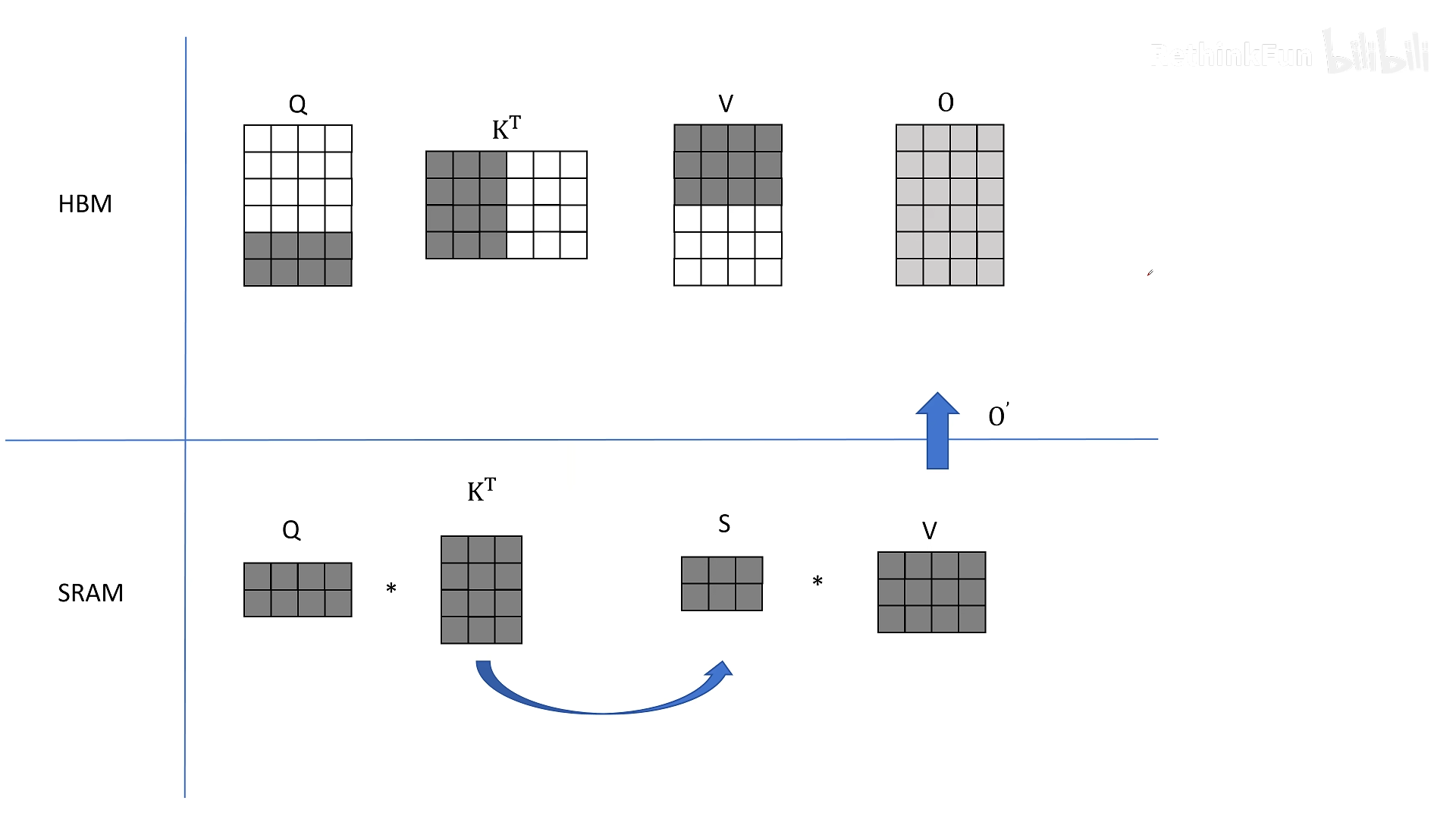
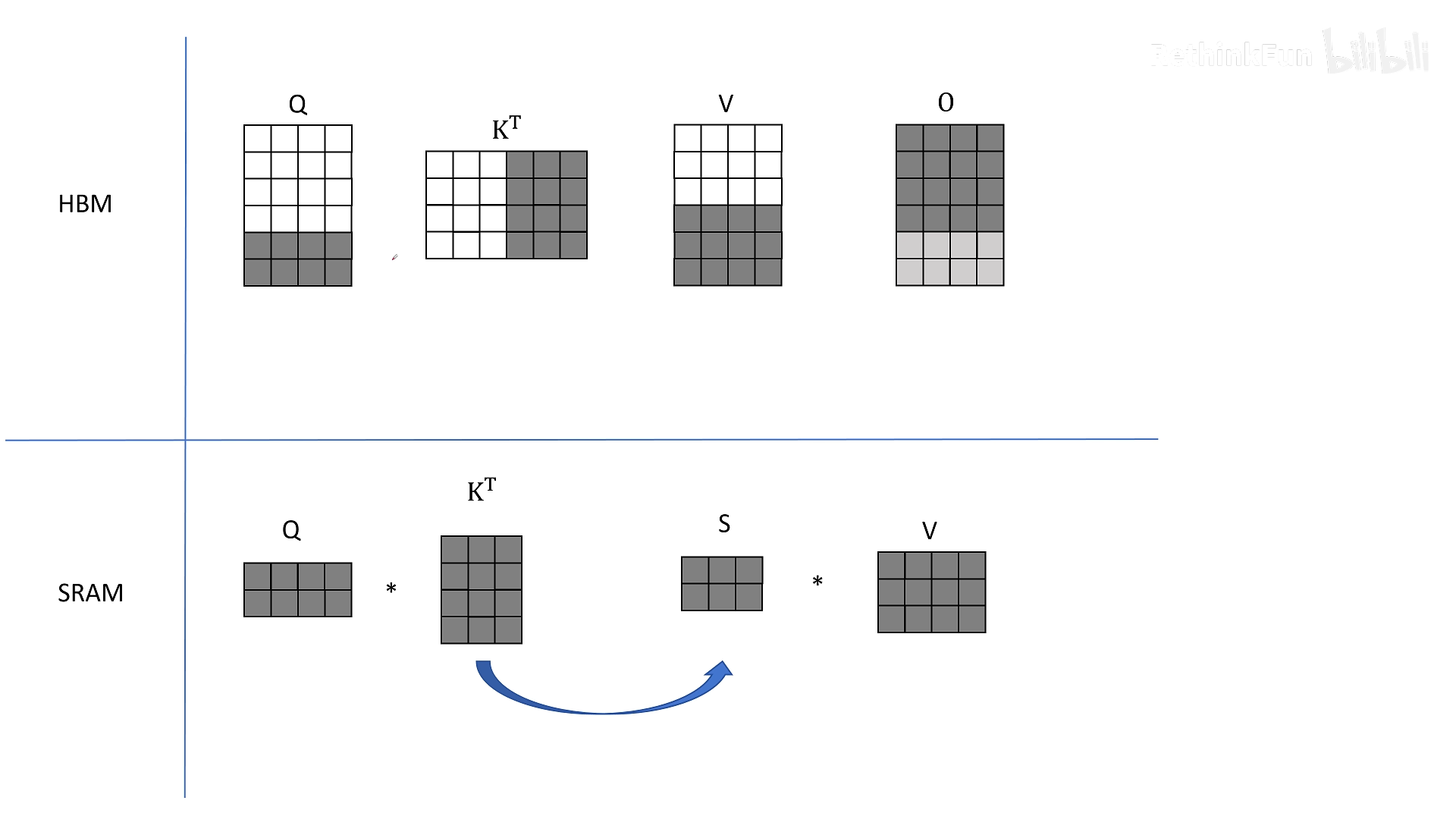
- 从 HBM 加载 Q 的前 2 行(分块)、Kᵀ 的前 3 列和 V 的前 3 行到 SRAM。
- 计算小矩阵乘法得到部分 S,并直接与 V 的分块相乘,得到 O 的部分累加结果(不是最终结果,因为只用了 V 的前 3 行)。
- 将 O 的部分结果写回 HBM(保存中间和)。
- 保持 K、V 分块不变,从 HBM 加载 Q 的下一个分块,计算并累加。
- 处理完所有 Q 分块后,换到 K、V 的下一个分块,重新从 HBM 加载之前保存的 O 中间结果,与当前 K、V 分块的计算结果相加,更新 O。
- 反复进行,直到所有分块处理完毕。
关键点:整个过程中,S 矩阵从未被写入 HBM,只在 SRAM 中临时存在,然后立即用于后续计算。这大大减少了 IO 次数。
三、分块计算 Softmax 的挑战与解决方案
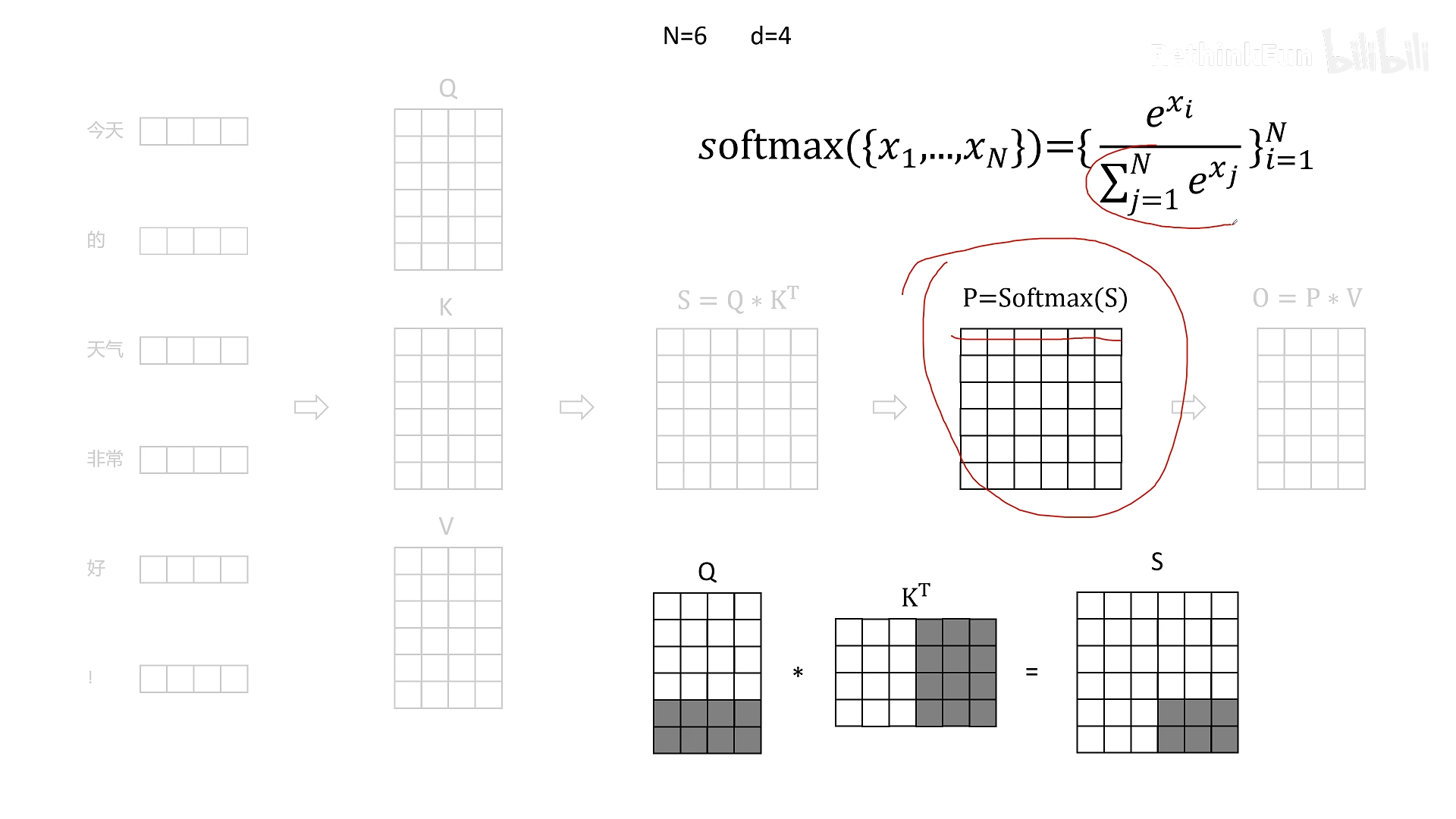
但是,Softmax 是按行计算的,且需要整行的所有元素才能求出分母(指数和)。分块后,每个块只有部分元素,无法直接计算 Softmax。为此,Flash Attention 采用了在线 Softmax(Online Softmax)技术。
Standard Safe Softmax 回顾
为了防止指数运算溢出(例如 x=12 时 exp(12) 超过 FP16 表示范围),标准做法是:

分块 Softmax 推导
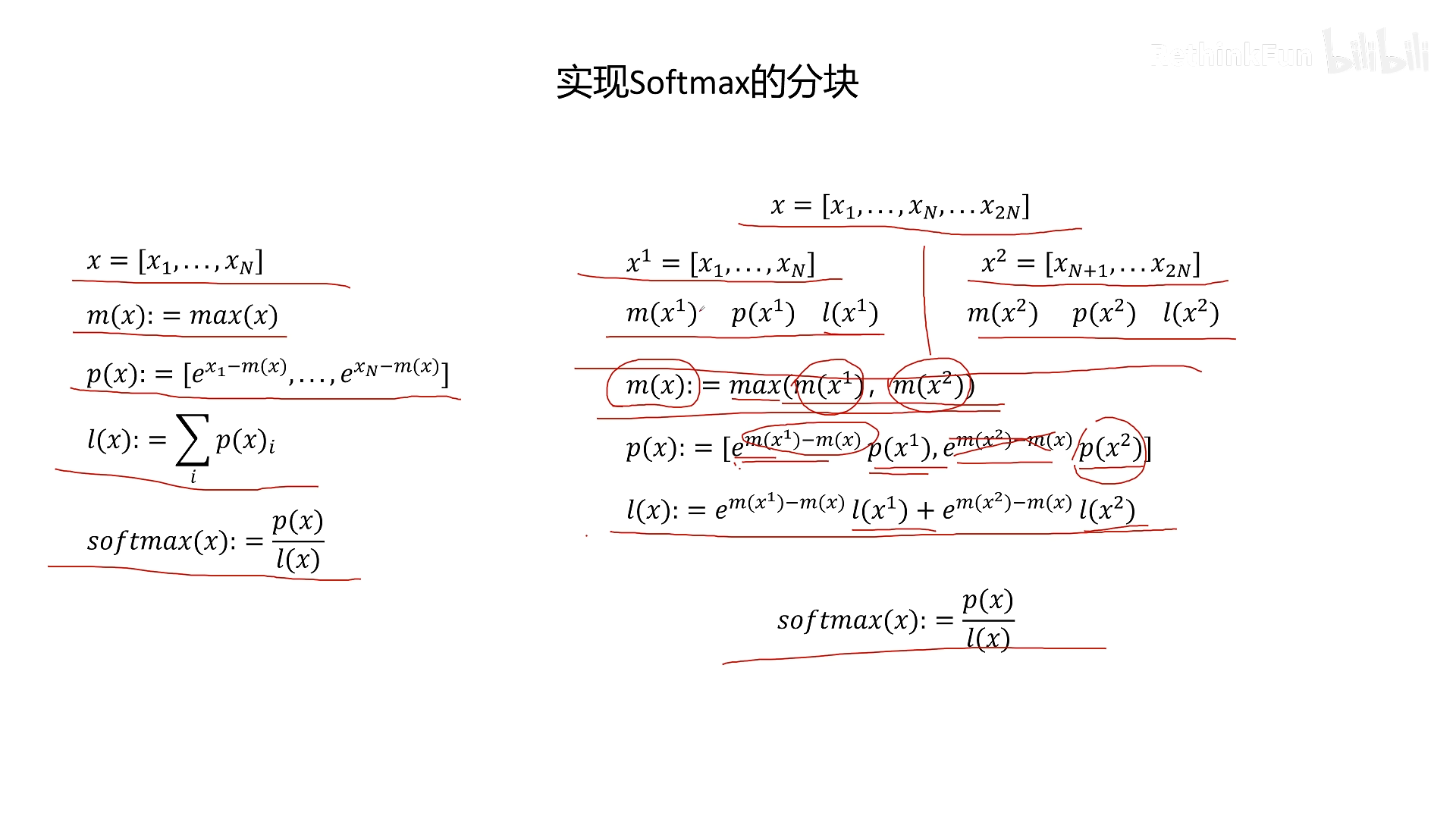
假设我们将一行的 N 个元素分成两个块:块1(1~N)和块2(N+1~2N)。每个块单独计算自己的局部最大值 m₁、m₂ 以及局部和 ℓ₁、ℓ₂。目标是得到全局最大值 m 和全局和 ℓ,进而计算整个行的 Softmax。
关键公式:
- 全局最大值 m = max(m₁, m₂)
- 对于块1:原始 exp(xᵢ – m₁) 需要调整为 exp(xᵢ – m)。由于 m = max(m₁, m₂),假设 m = m₂ > m₁,则块1的每个元素需要乘以一个系数:exp(m₁ – m)(小于 1)。调整后的块1和为 ℓ₁ × exp(m₁ – m)。
- 对于块2:因为 m₂ = m,所以块2的 exp(xᵢ – m) 就是原先的 exp(xᵢ – m₂),各项不变。
- 全局和 ℓ = ℓ₁ × exp(m₁ – m) + ℓ₂
- 则整个行的 Softmax 值 = 调整后的 exp(xᵢ – m) / ℓ
实现方法:计算每个分块时,只需要额外保存该块的最大值 m_block 和局部和 ℓ_block。这些统计量每行只占一个数字,内存开销极低。在合并时,做少量额外计算(乘法、比较),但相比减少的 IO 时间,这些额外计算可以忽略不计。
四、伪代码实现(Flash Attention 前向)
(参考论文中的伪代码,这里给出简化版 C 风格伪码)
输入:Q, K, V (N×D 矩阵,在 HBM 中)
SRAM 大小 M
过程:
// 计算分块大小
Bc = ceil(M / (4*D)) // 列分块(K、V 的分块大小)
Br = min(ceil(M / (4*D)), D) // 行分块(Q 的分块大小),限制 Br ≤ D
初始化 O = zeros(N, D) // 在 HBM 中
初始化 L = zeros(N, 1) // 存储每行的指数和
初始化 M = zeros(N, 1) // 存储每行的最大值
// 外循环:遍历 K、V 的分块(按列分块)
for block_j from 0 to N-1 step Bc:
从 HBM 加载 K_j (Br×D 块) 到 SRAM
从 HBM 加载 V_j (Br×D 块) 到 SRAM
// 内循环:遍历 Q 的分块(按行分块)
for block_i from 0 to N-1 step Br:
从 HBM 加载 Q_i (Br×D 块) 到 SRAM
从 HBM 加载 O_i (Br×D 块) 到 SRAM(旧的累加结果)
从 HBM 加载 L_i (Br×1) 和 M_i (Br×1) 到 SRAM
// 1. 计算当前分块的 S = Q_i × K_jᵀ
S_ij = Q_i * K_jᵀ (在 SRAM 中)
// 2. 计算当前分块的 m、l(局部统计量)
m_new = row_max(S_ij) // 每行最大值
l_new = row_sum(exp(S_ij - m_new)) // 每行指数和
// 3. 与之前累加的结果合并(使用分块 Softmax 公式)
m_old = M_i // 从 HBM 读取的旧最大值
M_i = max(m_old, m_new) // 新最大值
// 合并每行的 l 和 O
// O_new = diag(l_old / l_new * exp(m_old - M_i)) * O_old + diag(exp(m_new - M_i) / l_new) * (S_ij * V_j)
// 简化写法:
factor_old = l_old * exp(m_old - M_i) / l_new
factor_new = exp(m_new - M_i) / l_new
O_i = diag(factor_old) * O_old + diag(factor_new) * (S_ij * V_j)
L_i = l_old * exp(m_old - M_i) + l_new // 更新全局和
// 4. 将更新后的 O_i, L_i, M_i 写回 HBM
写出 O_i 到 HBM
写出 L_i 和 M_i 到 HBM
// 最终输出 O(每行已经除以最后的 L_i,因为 O 在更新时已经归一化)
返回 O
解释:上述伪代码在每次内循环中,用当前分块更新 O 和统计量。注意,O 的更新公式中使用了“对角矩阵”的形式,实际上就是给每行乘一个系数,相当于先“反归一化”旧的 O(乘以旧的 ℓ),再“归一化”到新的 ℓ,保证数值正确。
关于分块大小公式
- Bc = ceil(M / (4*D)):原因是在 SRAM 中需要同时存放 Q 的一个分块、K 的一个分块、V 的一个分块,以及 O 的一个分块,共 4 个分块矩阵。每个矩阵大小约为 Br×D 或 Bc×D,但实际实现中取整后保证总大小不超过 M。
- Br = min(Bc, D):限制 Q 分块的行数不超过 D,防止中间矩阵 S 太大(S 的大小是 Br×Bc,最大为 D×D)。
五、反向传播:利用重计算减少显存
在前向计算中,我们并不保存 S 和 P 等大矩阵,只保存了每行的最大值 m 和指数和 ℓ(N 个浮点数)。反向传播时,我们可以从 HBM 加载 Q、K、V 的分块以及 m、ℓ,重新计算出 S 和 P 的局部值,进而计算梯度。这与梯度检查点(Gradient Checkpointing)思想一致——用计算换显存。
具体来说:
- 从 HBM 加载所需的 Q_i、K_j、V_j 分块,以及对应的 m_i、ℓ_i。
- 重算 S_ij = Q_i × K_jᵀ
- 重算 P_ij = exp(S_ij – m_i) / ℓ_i (这里 ℓ_i 已更新到全局,但反向时只需使用前向保存的ℓ即可,因为ℓ是标量)
- 沿反向传播链,计算 dQ、dK、dV 的梯度(同样分块进行)。
由于重计算避免了保存 N×N 的中间矩阵,显存占用从 O(N²) 降到 O(N)。虽然增加了部分计算量(约 1/3 额外计算),但 IO 访问量大幅减少,总体训练时间缩短到原来的 1/6(论文数据)。
六、Flash Attention 2:工程优化
Flash Attention 2 在原理上类似,但做了以下关键改进:
- 减少非矩阵乘法的操作:前向和反向中,将一些标量运算(如更新 ℓ、m)整合到矩阵乘法中间,通过 Tiling 和寄存器重用,减少不必要的计算。
- 内外循环交换:将 Q 作为外循环,K、V 作为内循环,使得 SRAM 中的 K、V 分块被更多 Q 分块重用,进一步减少从 HBM 加载 Q 的次数(反向同理)。
- 增加并行度:针对不同 head 和不同行,可以并行处理,提高 GPU 利用率。
- 利用因果掩码:在解码任务中,如果确定一个分块是上三角(被 mask 掉),则跳过该分块的计算,节约计算量。
七、总结与思考
Flash Attention 通过精细的 IO 意识,将标准 Attention 的显存和计算瓶颈转化为对芯片缓存的充分利用,实现了显著加速。它不需要修改模型架构,也不牺牲精度,已成为 LLM 训练(如 LLaMA、GPT 系列)的标配。
关键点回顾:
- 标准 Attention 中,中间矩阵 S 和 P 是 IO 瓶颈。
- Flash Attention 通过分块和算子融合,避免中间结果写回 HBM。
- 分块 Softmax 通过维护每行的最大值和指数和,实现精确合并。
- 反向传播采用重计算,以少量额外计算换取显存和 IO 节省。
思考题
问题 1:Flash Attention 如何保证计算结果与标准 Attention 完全一致?
答案:它使用了分块 Softmax 的精确数学推导(如文中所示),合并时通过维护每行的最大值 m 和指数和 ℓ,保证了计算结果的数学等价性,不存在近似或截断误差。
问题 2:Flash Attention 在反向传播时为什么不需要保存 S 和 P?它如何获得梯度所需的值?
答案:前向时只保存了每行的 m 和 ℓ(只需要 N 个标量)。反向时,从 HBM 加载 Q、K、V 的分块以及对应的 m、ℓ,重新计算当前分块的 S 和 P,再按标准 Attention 的反向公式计算梯度。这类似于梯度检查点技术,用计算量换取显存。
问题 3:如果序列长度 N 非常长(例如 128K),Flash Attention 的显存占用如何增长?
答案:显存占用主要来自 Q、K、V、O 以及少量统计量,这些都与 N 成线性关系。中间结果 S、P 不再存储,因此显存增长为 O(N),而非标准 Attention 的 O(N²)。这使得超长序列训练成为可能。
