为什么需要RNN?
想象一下,你给普通的图像识别网络看一张猫咪的照片,它只需要看这一帧,就能立刻告诉你——这是猫。这种网络处理的是静止的、孤立的信息,每次决策独立完成,不需要任何上下文。
但现实世界中有大量数据并不是孤立的,它们有顺序、有时间,构成序列。比如一部悬疑电影,如果你直接跳到第10分钟,根本看不懂凶手是谁;只有从第1分钟的伏笔到第5分钟的线索,再到第10分钟的揭秘,整个故事才能串联起来。
这就是传统网络的困境:它们只能看照片,无法理解电影。
而RNN的超能力正在于此——它能带着一个记忆包,在时间轴上逐步处理序列数据,把每一步的信息积累起来,传递给下一步。因为记得第1分钟,才能看懂第10分钟。这就是RNN与传统网络最本质的区别:感知时间,理解顺序。
RNN的核心结构
折叠视图
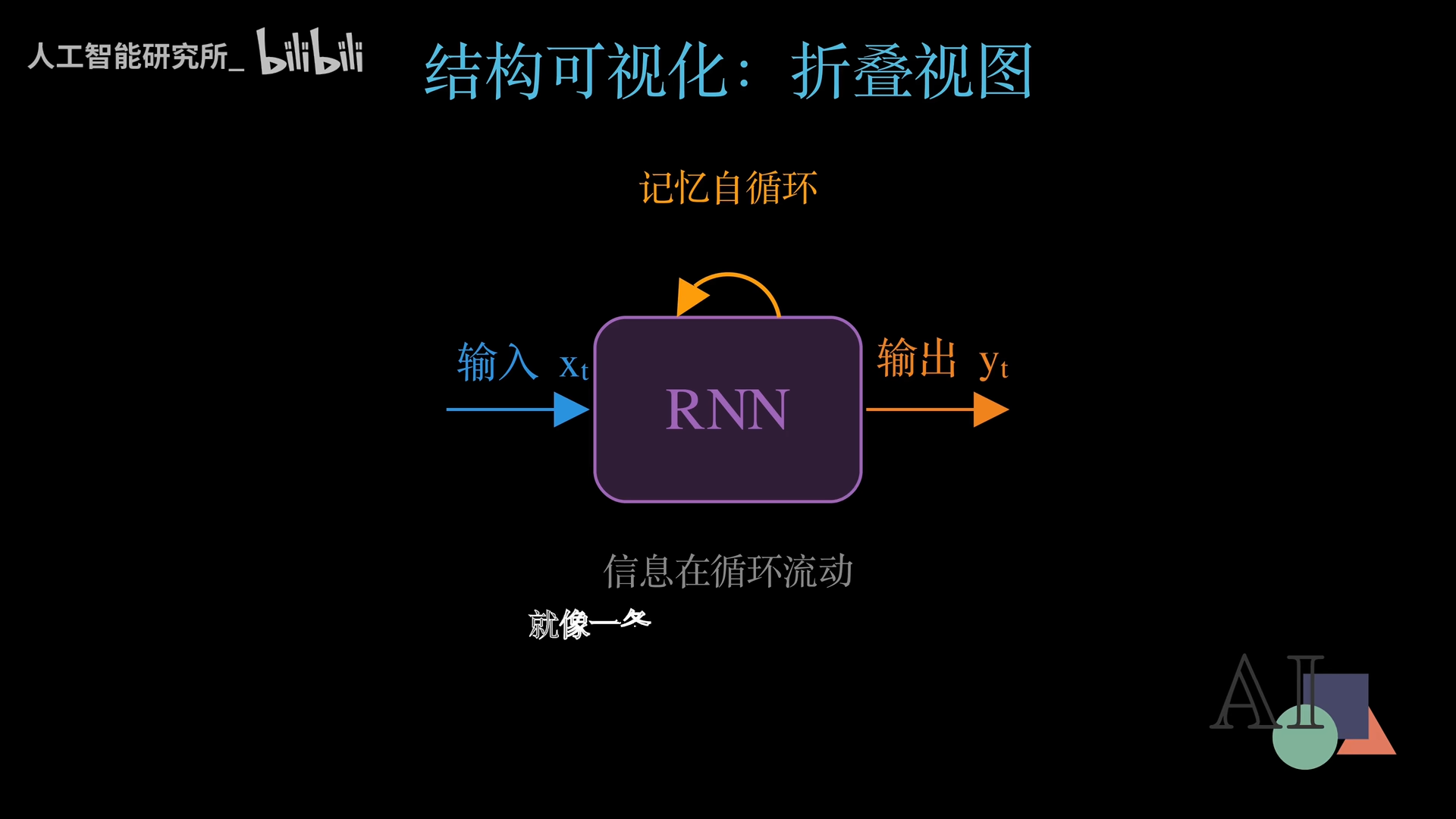
屏幕中央的紫色方块就是一个RNN单元。从左边进来的蓝色箭头代表当前时刻的输入X(比如当前这个词、字符或帧数据),从右边出去的橙色箭头代表当前时刻的输出Y(网络给出的预测结果)。
最关键的是那条金色的自循环箭头——它从RNN单元的顶部出发,绕了一圈又回到自己。这个循环代表记忆的回路:网络把自己上一时刻的状态重新输入给自己,就像一条蛇咬住了自己的尾巴,信息在循环流动。
展开视图
将折叠的循环沿时间轴展开,可以看到同一个RNN网络在三个不同的时间步(t-1、t、t+1)分别处理了三个词:I、love、AI。
- 每个时间步,网络从下方接收当前输入,从上方输出当前预测结果。
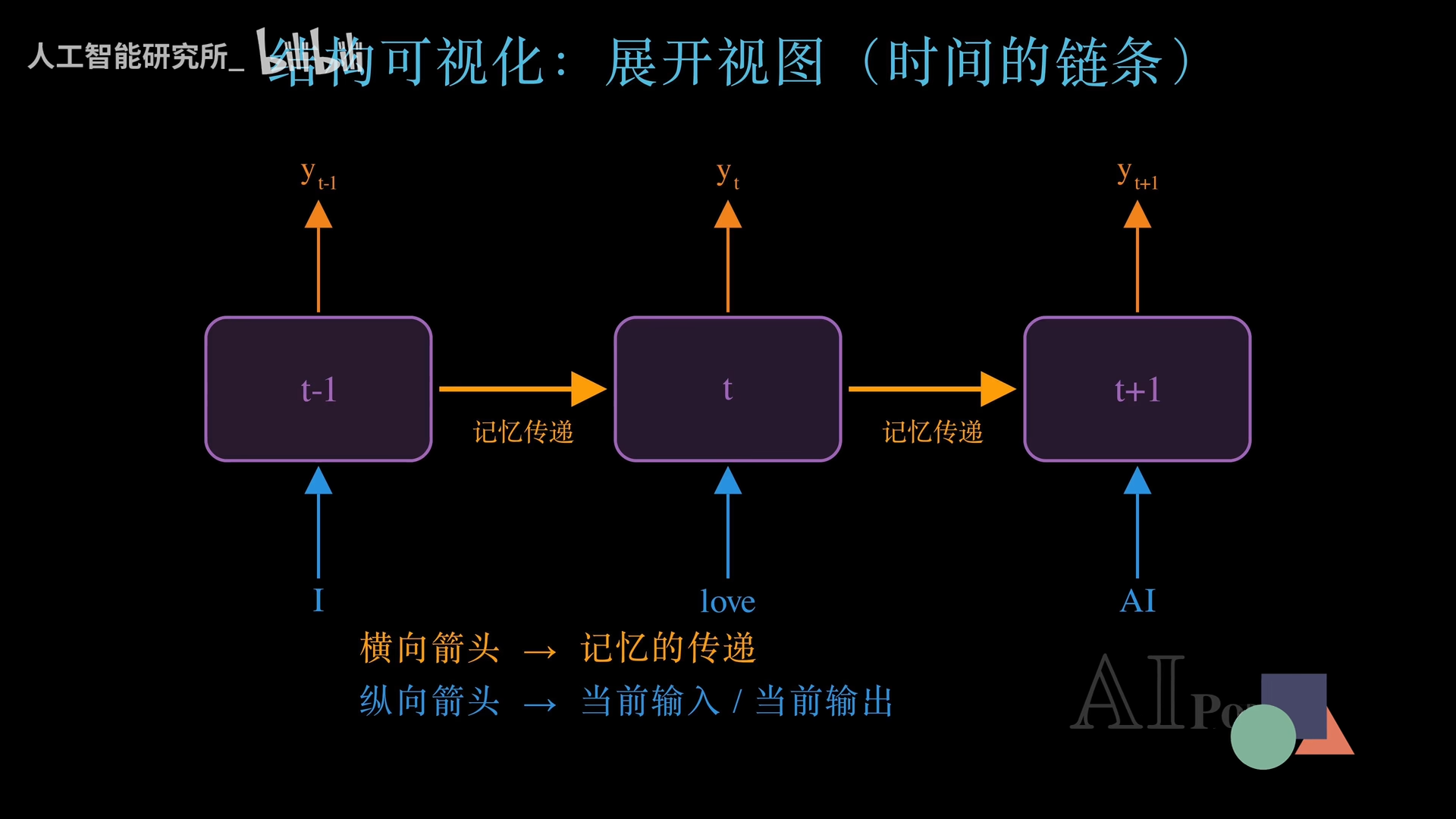
- 横向的金色箭头代表记忆的传递:每个时间步处理完后,都会生成一个隐藏状态H(Hidden State),H就像一个记忆包被传递给下一个时间步,让下一步能够知道之前发生了什么。

纵向是输入和输出,横向是记忆的流动——这两条轴共同构成了RNN的计算骨架。
一个非常重要的细节:这三个方块不是三个不同的网络,而是同一个网络在不同时刻的快照,它们共享完全相同的参数。这就是RNN的参数共享机制。
RNN的数学公式
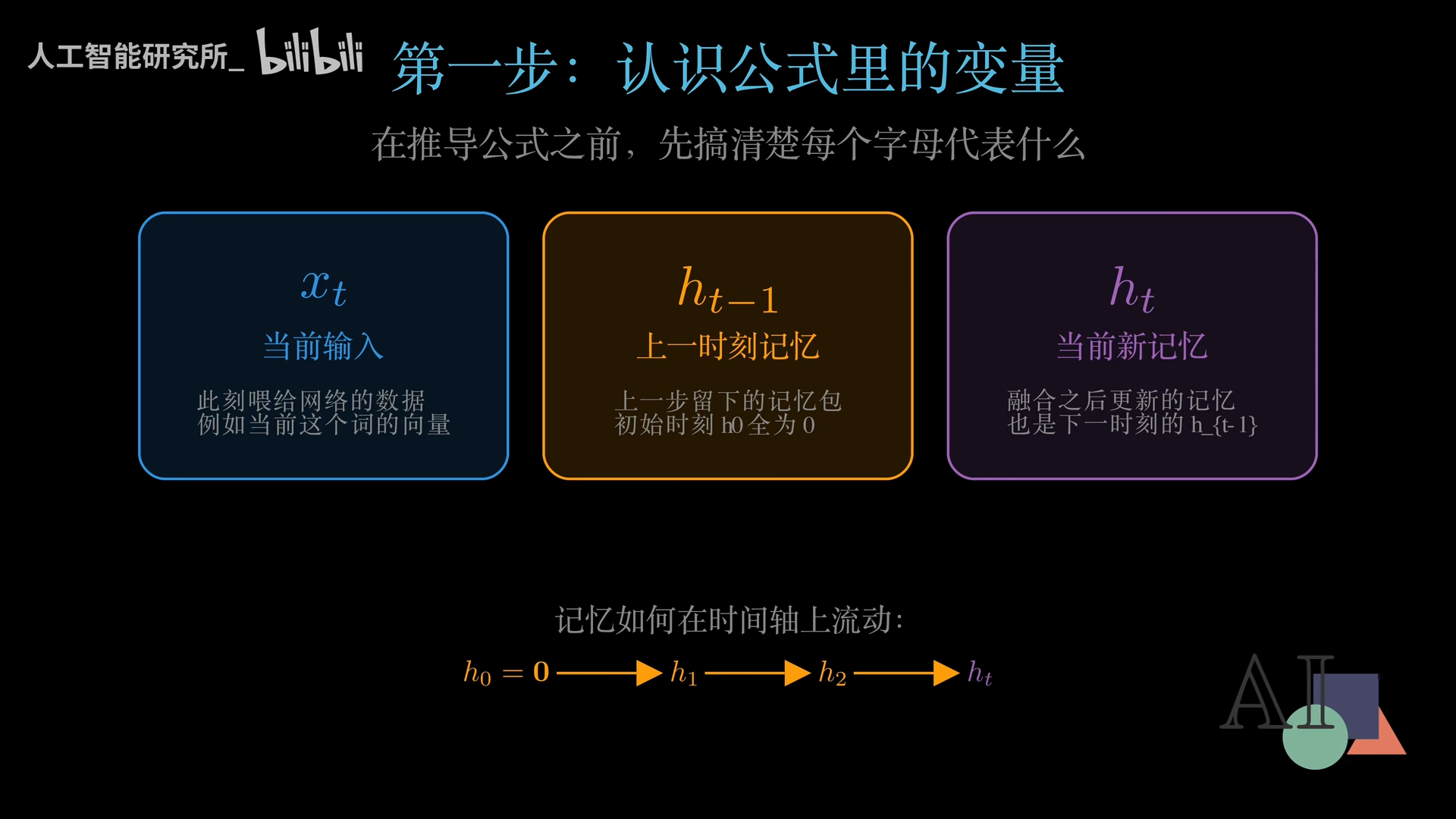
在推导公式之前,我们先认识三个最核心的变量:
| 变量 | 含义 | 类比 |
|---|---|---|
| XT(蓝色) | 当前输入 | 新鲜食材 |
| Ht-1(金色) | 上一时刻的记忆 | 上锅的半成品 |
| Ht(紫色) | 当前新记忆 | 融合后的新菜 |
在最开始的第1步,H₀全部初始化为零,网络从一片空白出发。
核心计算公式
Ht = tanh( Wx · Xt + Wh · Ht-1 + b )
逐项解读:
- Wx · Xt:处理新信息。权重矩阵Wx决定当前输入有多大程度被重视,就像给食材调味。
- Wh · Ht-1:调用旧记忆。权重矩阵Wh决定过去的经验对现在的影响有多大,就像厨师根据上一锅的火候调整这一锅。
- 相加融合:最直接的信息融合方式,简单却有效。
- b(偏置):可学习的基准调节量,让网络保留一定的默认倾向。
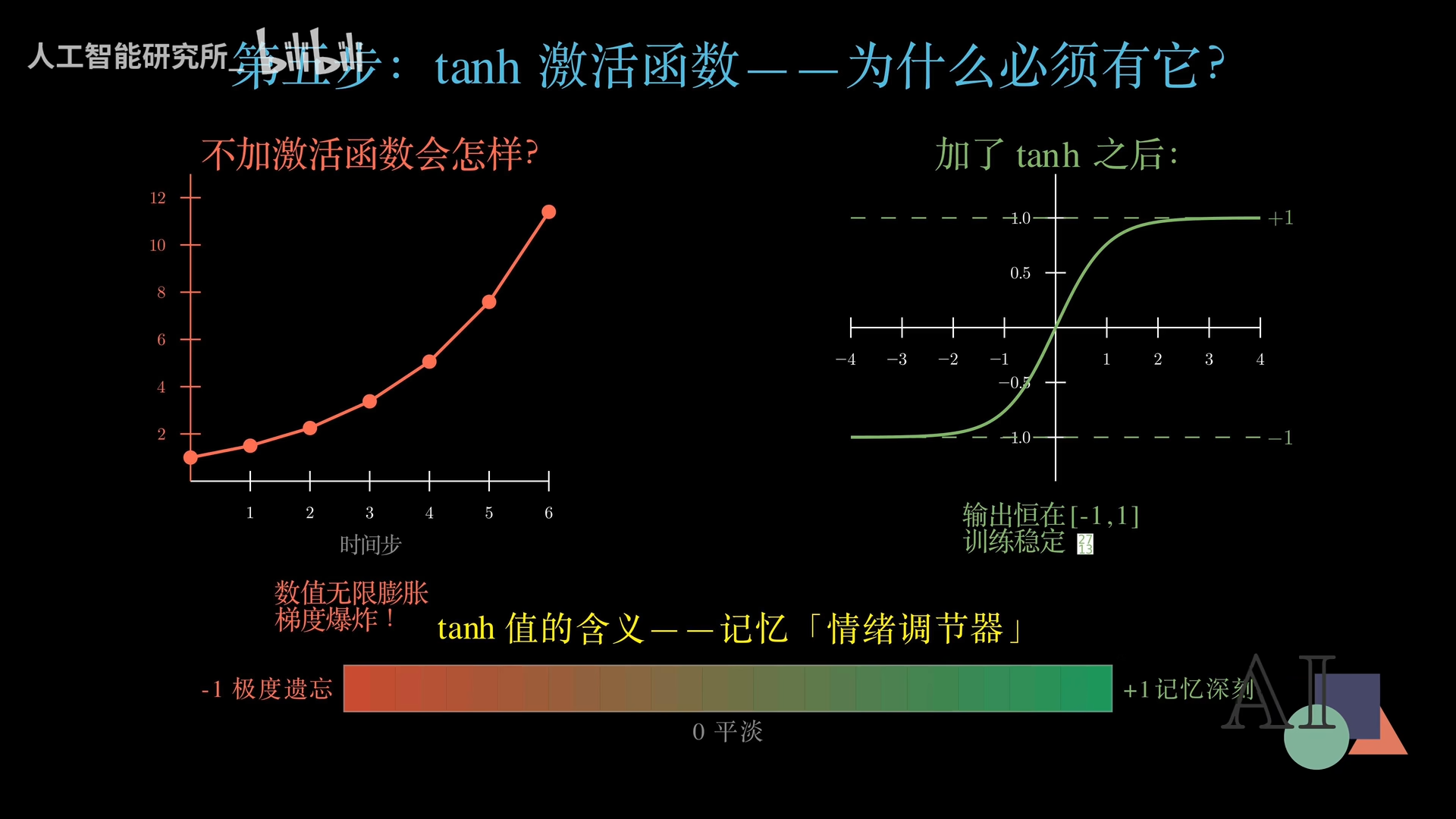
- 激活函数 tanh:将数值压缩到-1到1之间。如果没有激活函数,每个时间步的数值会不断累乘,导致梯度爆炸,网络完全无法训练。激活函数让网络学会了有所取舍:接近1意味着深刻记住,接近0意味着平淡处理,接近-1意味着极度遗忘。
输出层

有了新记忆Ht后,通过另一层变换(softmax函数)将结果转化为词表中每个词的概率分布,概率最高的词就是本时刻的预测输出。
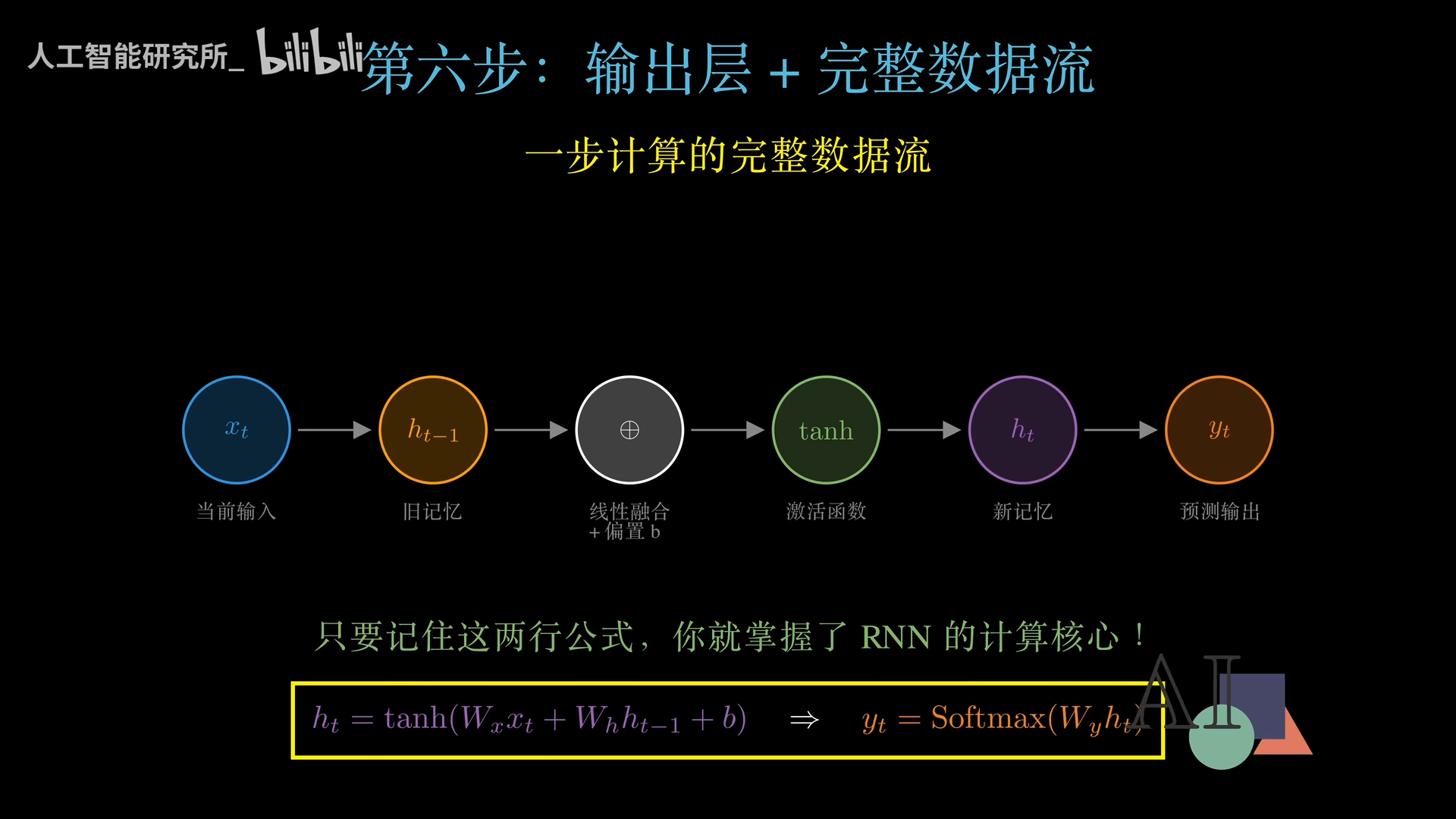
只要记住这两行公式,你就掌握了RNN的全部计算核心。
实战案例:预测下一个词
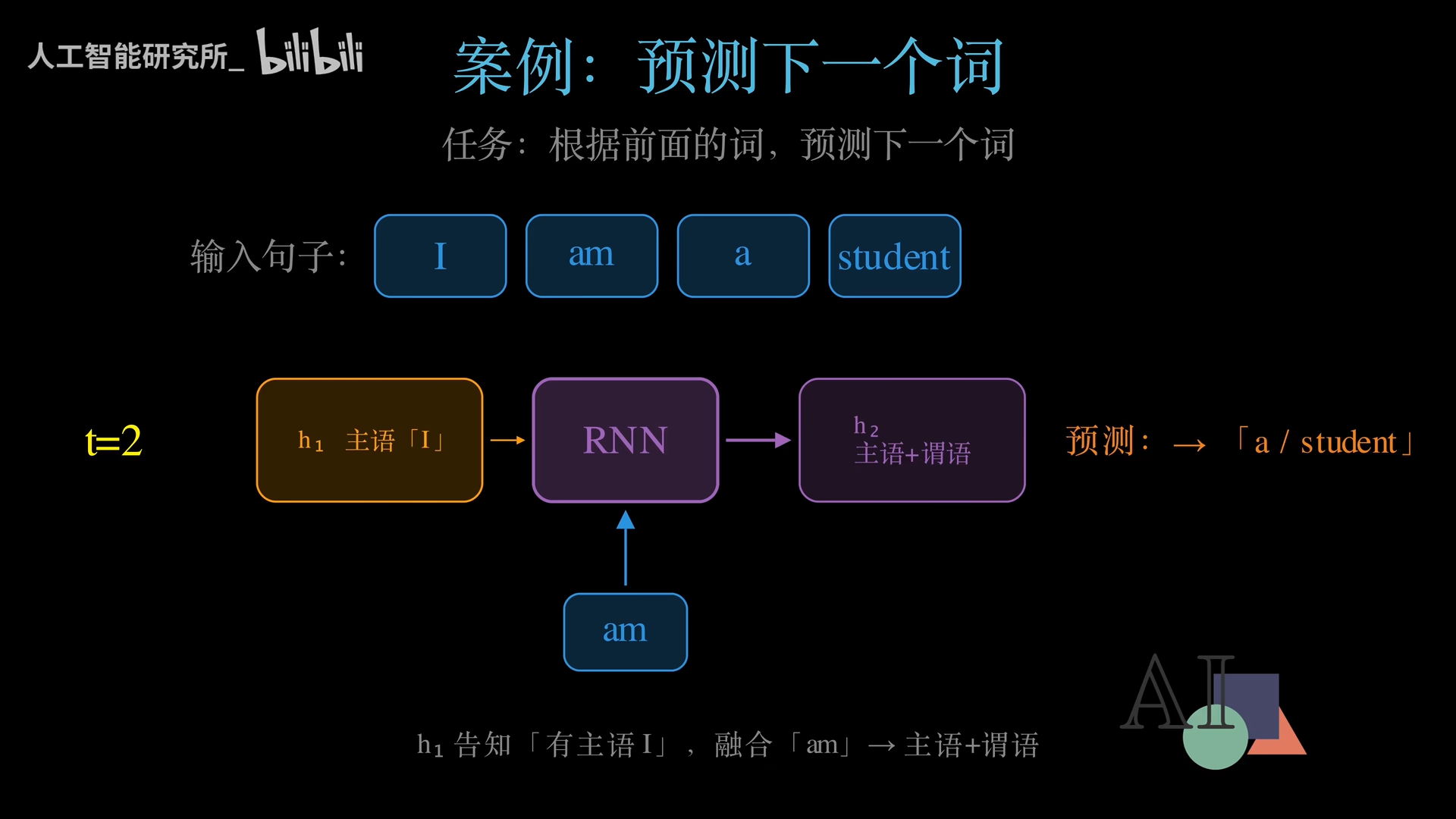
用RNN逐词处理句子 "I am a student",预测下一个词:
| 时间步 | 输入 | 记忆状态 | 预测输出 |
|---|---|---|---|
| t=1 | I | H₀(全零)→ H₁(含主语信息) | am |
| t=2 | am | H₁(含主语信息)→ H₂(主语+谓语) | a / student |
| t=3 | a | H₂(主语+谓语)→ H₃(完整语境) | student(高置信度) |

这个案例完美展示了RNN的工作方式:正是因为每一步都记得之前的内容,才能做出越来越准确的预测。 关键在于Wh·Ht-1这一项——它是RNN记忆的物理实现。
参数共享机制
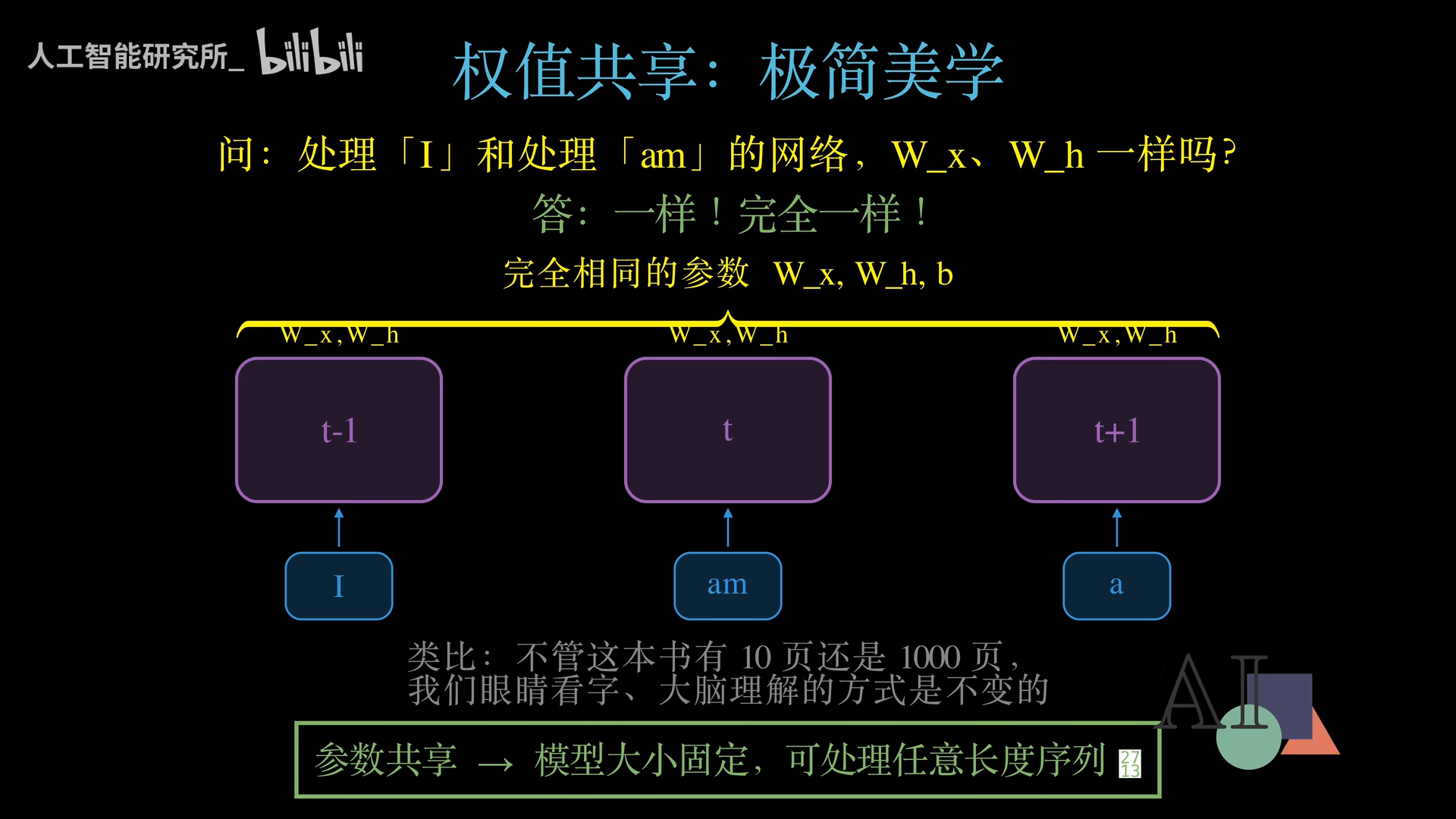
处理I和处理am的网络,它们的参数Wx、Wh是同一套吗?
答案是完全一样。 不管是t-1步、t步还是t+1步,所有时间步用的都是同一套参数。
用一个类比来理解:不管一本书有10页还是1000页,我们眼睛看字、大脑理解文字的方式是不变的。同样,不管输入序列有多长,RNN处理每个时间步的方式(也就是那套参数)始终如一。
这个设计的好处:
- 模型大小固定:可以处理任意长度的序列,参数量不随序列长度增长。
- 传统全连接网络如果每个时间步都用独立参数,处理长文本时模型将大得无法承受。
参数共享是RNN设计中一种真正的极简美学。
总结:RNN核心四句话

- 一入一出藏状态:每一步都有一个输入X、一个输出Y,但最核心的是中间流动的隐藏状态H——它是记忆的载体。
- 当前过去加一块:Wx·Xt处理当前输入,Wh·Ht-1调用过去记忆,两者相加融合——这是RNN运转的核心动作。
- 激活函数把范围盖:tanh函数把计算结果压缩到-1~1之间,防止数值爆炸,让训练保持稳定。
- 参数共享真不赖:无论序列多长,都用同一套参数处理,模型大小固定,泛化能力强。
这四句话就是RNN的完整精髓。
RNN的局限性
RNN也有它的局限性:当序列非常长时,早期的记忆会随着时间步的增加逐渐淡化,这就是长期依赖问题。比如你很难指望RNN读完一本小说后还记得第一章的细节。
从数学上看,这是因为在反向传播过程中,梯度需要沿着时间步连乘,若权重矩阵的特征值小于1,梯度会指数级衰减(梯度消失);若大于1,则会指数级增长(梯度爆炸)。解决这个问题的是下一个重要角色——LSTM(长短期记忆网络),它引入了门控机制,让记忆的遗忘与保留变得更加智能。
思考题与答案
1. RNN和传统前馈神经网络(如CNN、全连接网络)最本质的区别是什么?
传统网络处理独立输入,无记忆能力;RNN通过隐藏状态传递信息,具备处理序列数据的能力,能感知时间顺序。
2. 为什么RNN需要激活函数(如tanh)?不加会怎样?
激活函数将输出压缩到有限范围(如-1到1),防止梯度爆炸。若不加激活函数,每一步的数值不断累乘,会导致训练完全失控。
3. 什么是RNN的参数共享?有什么好处?
所有时间步共用同一组权重参数。好处是参数量固定,不随序列长度增长,使模型能处理任意长度的序列并提升泛化能力。
4. RNN存在的主要问题是什么?有哪些改进方案?
主要问题是长期依赖问题(梯度消失/爆炸),导致长序列中早期记忆丢失。改进方案包括LSTM(引入遗忘门、输入门、输出门)和GRU(简化门控结构)。
