本文主要是笔者学习猛猿和DefTruth这两位大佬的文章之后进行的吸收重构,加上一些自己的理解,感兴趣的朋友也可以直接看看原文。
自 Transformer 架构诞生以来,大语言模型的能力边界被一次又一次地拓宽。如下图所示,其核心的 Multi-Head Attention 机制赋予了模型强大的上下文理解能力,但同时也带来了一个严峻的挑战:它的计算和内存复杂度都与输入序列长度 N 的平方成正比,即 O(N^2)。这个二次方瓶颈如同一道无形的墙,极大地限制了模型能够处理的上下文长度,并使得训练和推理成本急剧上升。
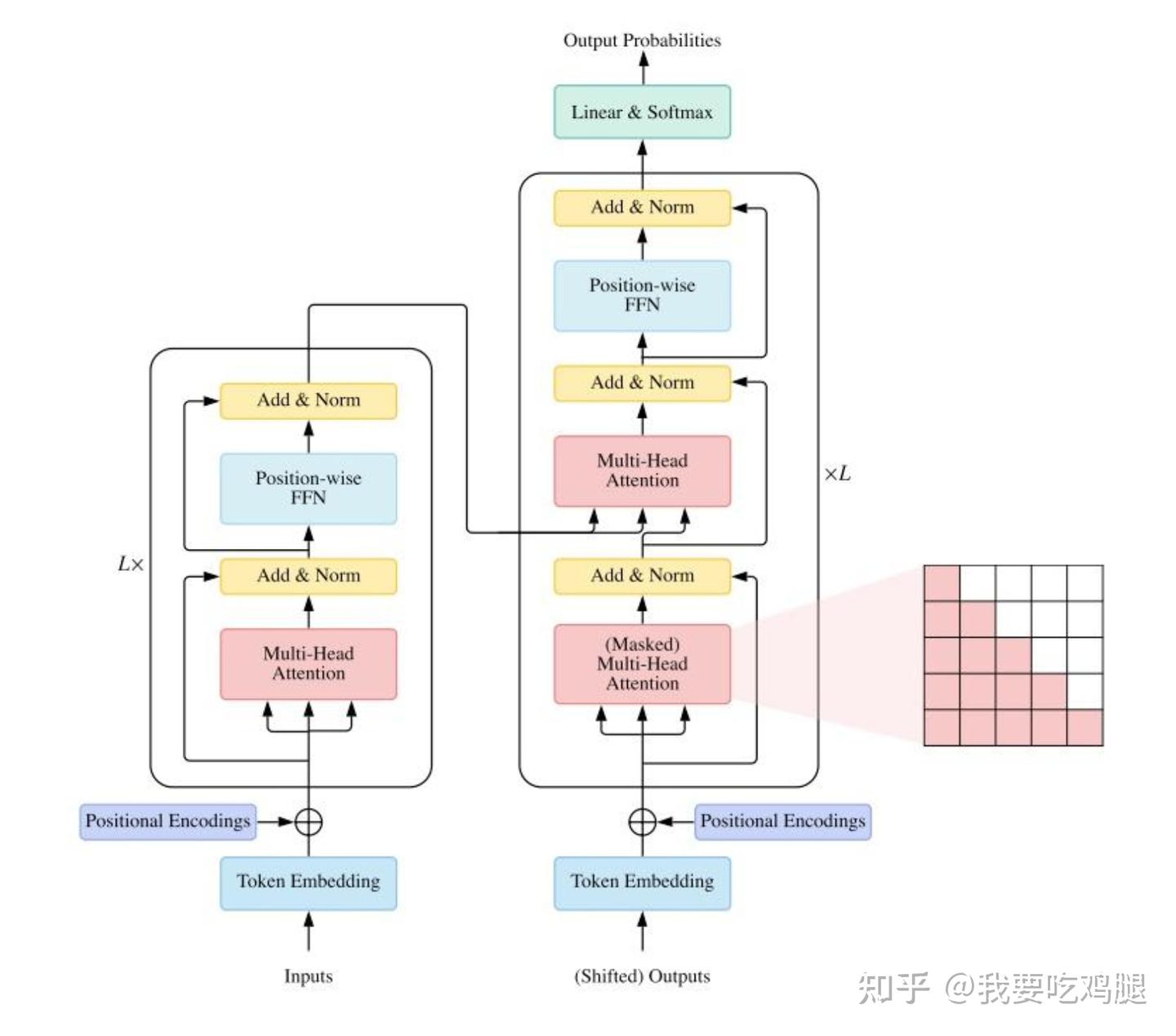
Transformer 架构
然而,一个看似纯粹的计算复杂度问题,其性能瓶颈的根源却常常隐藏在更深的地方。深入分析 GPU 的工作模式后我们发现,制约标准 Attention 性能的并非是 GPU 的浮点运算能力(FLOPs),而是对高带宽显存(HBM)的低效访问模式——这是一个典型的**内存限制(Memory-Bound)**问题。
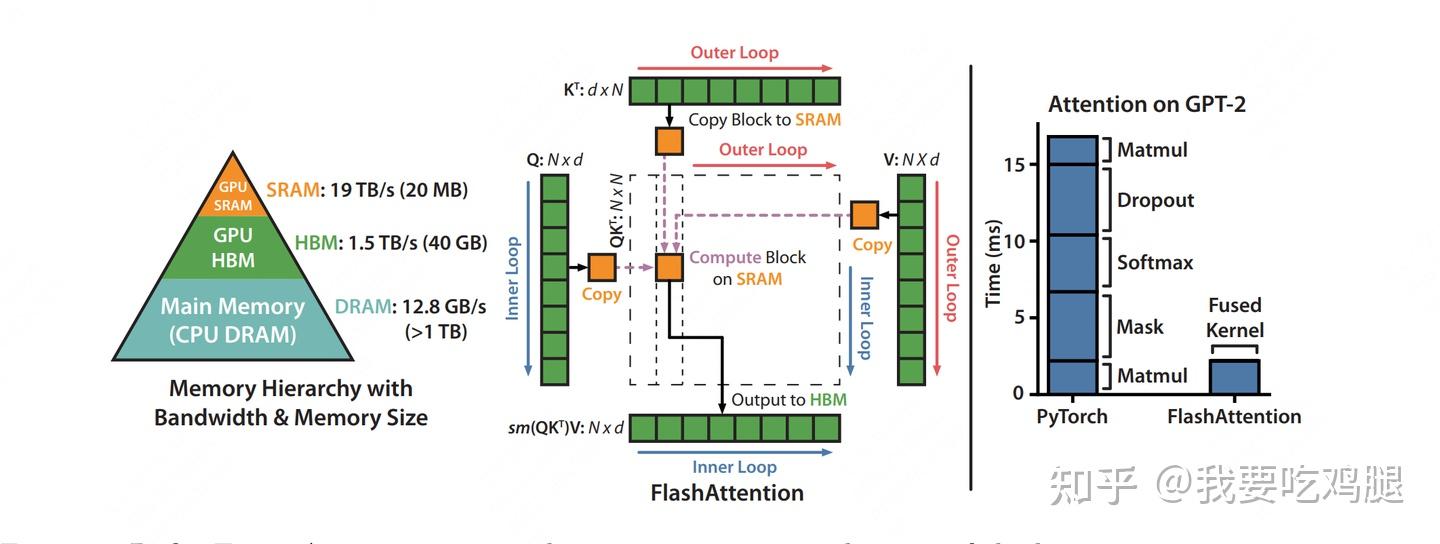
上图左侧的内存金字塔揭示了问题的核心:GPU 核心旁的片上缓存(SRAM)速度快如闪电(可达 19 TB/s),但容量极小(数十 MB);而外部的高带宽显存(HBM)虽然容量巨大(数十 GB),但访问速度却慢了一个数量级(约 1.5 TB/s)。标准的 Attention 实现没有充分利用这一硬件特性,它在计算过程中需要生成两个巨大的中间矩阵:S=QK^T 和 P=\text{softmax}(S),并反复将它们在慢速的 HBM 中读写。
上图右侧的性能对比更是将这种低效暴露无遗。标准 PyTorch 实现的 Attention,其总耗时是多个独立 GPU 操作(Kernel)的累加:两次矩阵乘法(Matmul),以及独立的 Mask、Softmax 和 Dropout 操作。每一次操作都意味着一次昂贵的数据往返于 HBM,大量时间被浪费在了“路上”。
为了从根本上破解此困局,Flash Attention 应运而生。它并非简单的修补,而是一种深刻理解硬件的 IO感知(IO-Aware) 算法,通过对计算流程的重构,实现了三大革命性目标:
- Fast (IO-Awareness):Flash Attention 的核心加速逻辑并非减少总计算量(FLOPs),而是通过**算子融合(Kernel Fusion)**技术,将上述所有独立操作合并到单个 GPU Kernel 中。数据一旦从 HBM 载入高速 SRAM,就会在其中完成所有计算,极大地减少了对 HBM 的访问次数。
- Memory-Efficient:它通过一种巧妙的在线计算(online-softmax)方法,完全避免了在 HBM 中实例化和存储 N \times N 大小的中间矩阵 S 和 P。这使得 Attention 部分的内存需求从 O(N^2) 戏剧性地降低到了 O(N)。
- Exact Attention:与稀疏注意力(Sparse Attention)等通过舍弃部分计算来换取速度的近似方法不同,Flash Attention 计算出的结果与标准 Attention 在数学上完全等同。它是一种无损的、精确的加速。
感觉看这个的大部分朋友可能都学过Cuda编程,这里面的HBM其实就是咱们平常说的gloabl memory然后高速SRAM就是我们平常用的shared memory。
本文将系统性地剖析 Flash Attention 的核心思想,首先从问题的根源(IO瓶颈)出发,然后详细讲解 V1 版本如何通过 Tiling 和Online Softmax 技术奠定基础,接着分析 V2 版本如何进行工程优化以追求极致性能,最后探讨其在推理场景下的高效变体 Flash Decoding。
要真正理解 Flash Attention 的巧妙之处,我们必须先深入其诞生的“土壤”——GPU 的硬件架构,并理解是什么从根本上制约了程序的运行速度。
1.1 GPU 内存层级与性能瓶颈
现代 GPU 是为大规模并行计算设计的超级计算机,但其内部并非铁板一块。性能的关键,在于理解其内存层级(Memory Hierarchy)。
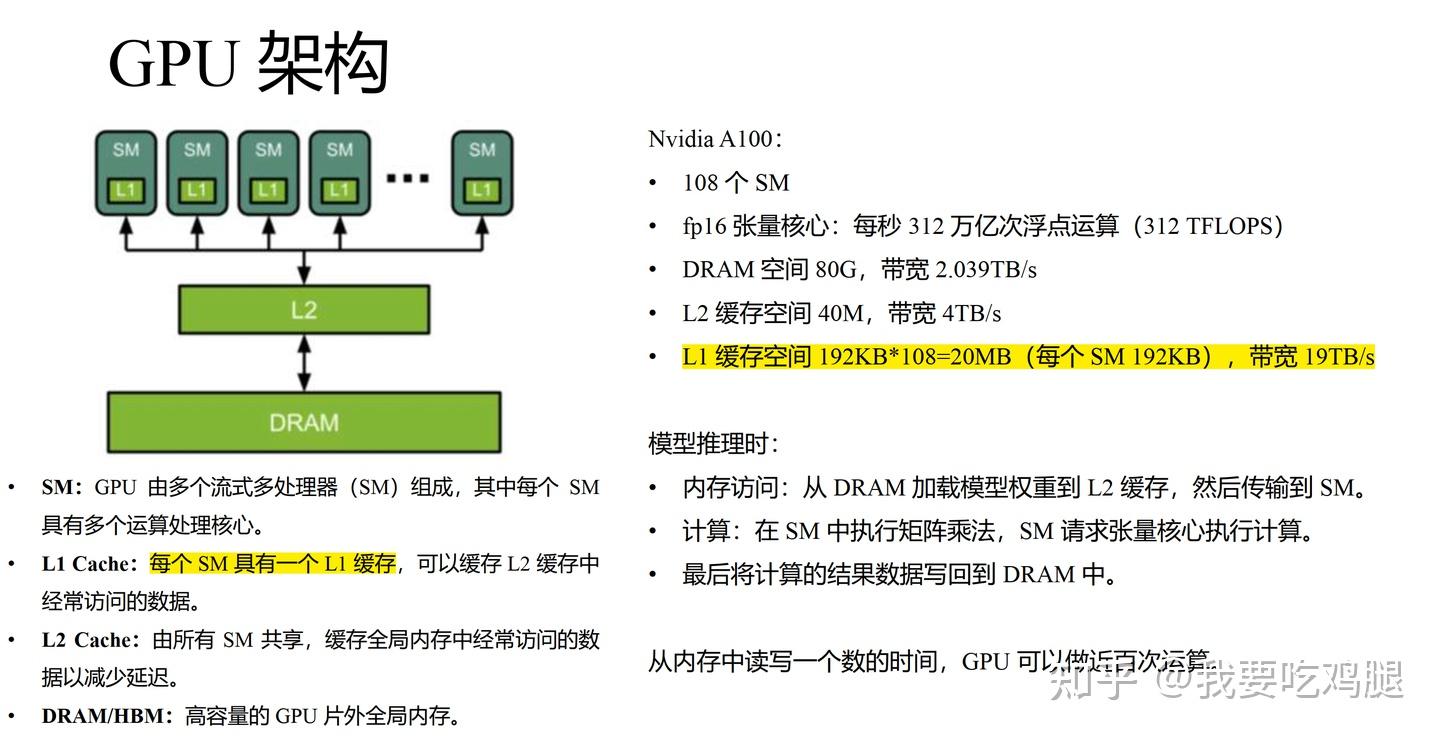
在前面我们可以看到,GPU 的内存系统可以被看作一个金字塔结构,从上到下,速度越来越慢,但容量越来越大:
- SRAM (L1 Cache / Shared Memory):这是金字塔的顶端。它位于每个 SM (Streaming Multiprocessor,流多处理器) 内部,是物理上最接近计算核心的内存。它的访问速度极快,以 A100 GPU 为例,其总带宽高达 19 TB/s。然而,它的容量却极其有限,A100 的每个 SM 只有 192KB 的 SRAM。
- L2 Cache:位于所有 SM 之间,是一个共享的缓存层。它的速度和容量介于 SRAM 和 HBM 之间,作用是减少对 HBM 的直接访问延迟。
- HBM (High Bandwidth Memory) / DRAM:这是金字塔的底座,也是 GPU 的主显存。它的容量巨大(例如 A100 有 40GB),但与 SRAM 相比,其访问速度则慢了一个数量级,A100 的 HBM 带宽约为 1.5 TB/s。
我们可以打一个比方:SRAM 是你手边的工具台,取用工具几乎不花时间;而 HBM 则是街对面的大型仓库,虽然能装很多东西,但每次去取货都要花费不少往返时间。一个高效的工作流程,必然是尽可能把常用工具都放在手边的工具台上,而不是频繁地往返于仓库。
基于这种硬件特性,一个算法的最终执行时间 T,取决于计算本身所耗费的时间 T_{cal} 和数据在各级内存间搬运所耗费的时间 T_{load} 中的最大值。
T = \max(T_{cal}, T_{load})
这就引出了两种截然不同的性能瓶颈:
- 计算限制 (Compute-Bound / Math-Bound):当 T_{cal} > T_{load} 时,程序的瓶颈在于 GPU 核心的运算速度。数据供应非常及时,计算单元正在全力运转。对于计算密集型任务(如大型矩阵乘法),这是我们期望达到的理想状态。
- 内存限制 (Memory-Bound):当 T_{load} > T_{cal} 时,程序的瓶颈在于内存带宽。GPU 强大的计算核心大部分时间处于“空等”状态,等待数据从慢速的 HBM 仓库中搬运过来。这就像一条拥堵的公路,无论汽车引擎多强大,也只能缓慢前行。
为了量化地判断瓶颈类型,我们可以引入一个关键指标——计算强度 (Operational Intensity)。
- 首先,我们定义硬件的两个性能上限:峰值算力 \pi (单位 FLOP/s) 和峰值内存带宽 \beta (单位 Byte/s)。
- 然后,我们定义算法的两个需求:总运算量 \pi_t (单位 FLOPs) 和总数据读写量 \beta_t (单位 Byte)。
计算强度的定义为:I = \frac{\pi_t}{\beta_t}
它的物理意义是:该算法每从内存中读写一个字节的数据,可以支撑多少次浮点运算。一个高计算强度的算法意味着数据被重复利用得很好,反之则意味着数据“用一次就扔”,导致频繁的内存访问。
因此,我们可以得出一个清晰的判断准则:当一个算法的计算强度 I,低于硬件本身的算力带宽比 \frac{\pi}{\beta} 时,它就是内存限制的。因为硬件搬运数据的速度,跟不上它消耗数据的速度。现在,让我们用真实数据来诊断标准 Attention 机制。以 A100-40GB SXM GPU 为例,其硬件的算力带宽比为:
\frac{\pi}{\beta} = \frac{312 \times 10^{12} \text{ FLOP/s}}{1555 \times 10^9 \text{ Byte/s}} \approx 201 \text{ FLOPs/Byte}
这意味着,在 A100 上,只有当一个算法的计算强度超过 201 FLOPs/Byte 时,它才有可能进入计算限制状态。
接下来,我们来分析标准 Attention 中计算 S=QK^T 这一步的计算强度。假设 Q 和 K 的维度均为 (N \times d),使用 fp16 精度(每个元素占 2 字节),其总运算量约为 2N^2d FLOPs,总数据读写量为 (2Nd + 2Nd + 2N^2) Bytes。
下表展示了在不同序列长度 N 和头维度 d 下的计算强度:
| N | d | 计算强度 (ops/bytes) | 瓶颈类型 |
|---|---|---|---|
| 256 | 64 | 43 | < 201, 内存限制 |
| 2048 | 64 | 60 | < 201, 内存限制 |
| 4096 | 64 | 62 | < 201, 内存限制 |
| 2048 | 128 | 114 | < 201, 内存限制 |
| 4096 | 128 | 120 | < 201, 内存限制 |
| 2048 | 256 | 205 | ≈ 201, 接近计算限制 |
| 4096 | 256 | 228 | > 201, 计算限制 |
从表格中可以清晰地看到,在绝大多数常见的配置下(特别是当头维度 d 较小时),标准 Attention 的计算强度都远远低于硬件的算力带宽比。后续的 Softmax、Dropout 等操作更是典型的低计算强度操作。这证明了,标准 Attention 性能不佳的根源,并非 GPU“算不动”,而是 HBM“喂不饱”,它是一个被 I/O 牢牢卡住脖子的内存限制问题。
1.2 标准 Attention 的“三趟式(3-pass)”计算流程
上一节我们从理论上诊断出标准 Attention 是一个内存限制(Memory-Bound)问题。现在,我们来深入其具体的计算流程,看看这种低效的 I/O 模式是如何在代码实现中产生的。
标准 Attention 的朴素实现可以被概念性地分解为一个“三趟式”的计算流程。这里的“趟(Pass)”指的是对 HBM 的一次完整的大规模数据读写周期。

Attention计算伪代码
结合上面的伪代码,我们将整个过程拆解如下:
第一趟 (Pass 1): 计算注意力分数 S = QK^T
-
操作: 这一步将查询矩阵 Q 与键矩阵 K 的转置相乘,得到原始的、未经归一化的注意力分数矩阵 S。
-
I/O 分析:
-
读: 从 HBM 中读取 Q 矩阵(大小为 N \times d)和 K 矩阵(大小为 N \times d)。
-
写: 将计算得到的 S 矩阵(大小为 N \times N)写回 HBM。
-
问题所在: 这一步直接在内存中生成了一个巨大的中间矩阵 S。它的尺寸与序列长度 N 的平方成正比,当 N 很大时(例如 N=8192),一个 fp16 精度的 S 矩阵就需要 8192 \times 8192 \times 2 \text{ bytes} \approx 128 \text{MB} 的显存,这还仅仅是单个注意力头。
第二趟 (Pass 2): Softmax 归一化 P = \text{softmax}(S)
-
操作: 对分数矩阵 S 的每一行应用 Softmax 函数,将其转换为概率分布,得到最终的注意力权重矩阵 P。
-
I/O 分析:
-
读: 从 HBM 中完整地读取刚刚写入的 N \times N 的 S 矩阵。
-
写: 将计算得到的 N \times N 的 P 矩阵再次写回 HBM。
-
深层问题:数值稳定的 Safe Softmax:为了防止在计算指数 e^x 时因 x 值过大而导致的数据溢出,实际工程实现中采用的是 Safe Softmax。这个过程在数学上可以分解为以下几个步骤:
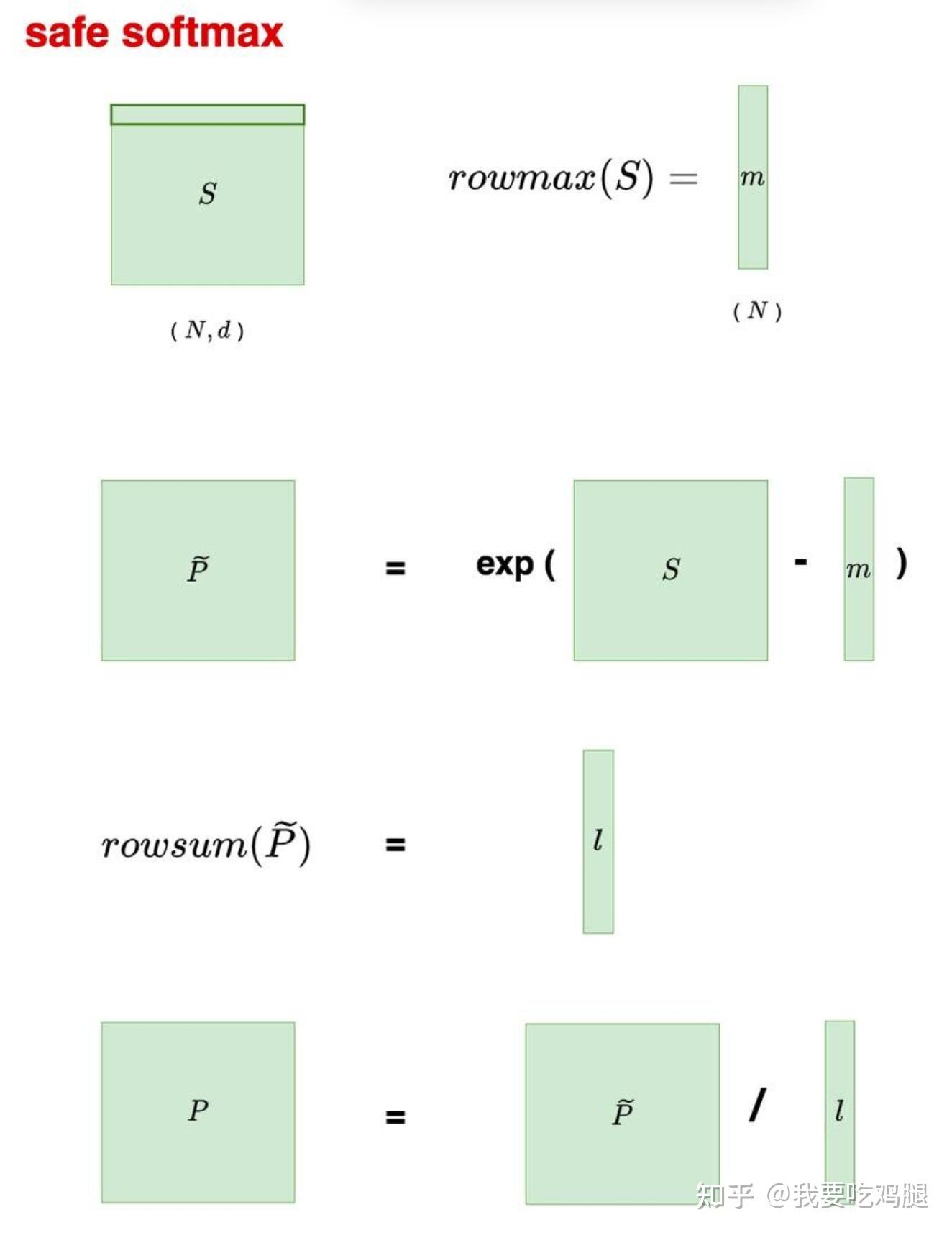
- 找到每行最大值: m = \text{rowmax}(S)
- 减去最大值并求指数: \tilde{P} = \exp(S – m)
- 求和得到归一化分母: l = \text{rowsum}(\tilde{P})
- 归一化得到最终概率: P = \tilde{P} / l
这个看似简单的 Safe Softmax 操作,如果用朴素的方式实现,其本身就是一个“三趟式(3-pass)”的过程,因为它需要对输入数据进行三次独立的遍历:
- 第一趟 (Pass 1): 寻找最大值。 遍历一次输入数据(x_1, …, x_N),找到全局最大值 m_N。其核心迭代公式为:m_i \leftarrow \max(m_{i-1}, x_i)
- 第二趟 (Pass 2): 计算分母。 再次遍历数据,利用已经得到的 m_N,计算归一化的分母 l_N。其核心迭代公式为:l_i \leftarrow l_{i-1} + e^{x_i – m_N}
- 第三趟 (Pass 3): 计算最终值。 第三次遍历数据,利用已经得到的 m_N 和 l_N,计算每个元素的最终概率值 P_i。其计算公式为:P_i \leftarrow \frac{e^{x_i – m_N}}{l_N}
这进一步加剧了对 HBM 的低效访问。
第三趟 (Pass 3): 计算输出 O = PV
-
操作: 将归一化后的权重矩阵 P 与值矩阵 V 相乘,得到加权聚合后的输出 O。
-
I/O 分析:
-
读: 从 HBM 中读取 N \times N 的 P 矩阵和 N \times d 的 V 矩阵。
-
写: 将最终的输出结果 O 矩阵(大小为 N \times d)写回 HBM。
总结:低效的根源
通过上述分析,标准 Attention 实现的根本问题暴露无遗:
- 巨大的显存占用: 算法在执行过程中,需要实实在在地在 HBM 中创建并存储两个 N \times N 的矩阵 S 和 P,导致了 O(N^2) 的显存空间复杂度。
- 海量的 I/O 流量: 整个计算流程被分割成独立的阶段,每个阶段都以 HBM 为媒介进行数据交换,总的 HBM 读写数据量达到了 O(Nd + N^2) 级别。
正是这种海量的、与计算量不相称的 I/O 流量,完美地印证了我们在 1.1 节中的诊断:标准 Attention 是一个被 I/O 牢牢卡住脖子的内存限制问题。这也为 Flash Attention 的优化指明了清晰的方向:必须打破这种分阶段、依赖 HBM 的计算范式。
二、Flash Attention V1:奠定基础的革命
在第一章中,我们明确了标准 Attention 的性能瓶颈在于对 HBM 的低效、多次读写。Flash Attention V1 的设计哲学正是对症下药:尽可能地减少对 HBM 的访问,将计算密集地保留在速度极快的 SRAM 中。为了实现这一目标,它引入了两大核心技术:Tiling(分块) 和 Kernel Fusion(算子融合)。
2.1 核心思想:Tiling 与 Kernel Fusion
2.1.1 Tiling (分块)
Tiling 是一种经典的计算优化技术,其思想是将一个大的、无法一次性处理的计算任务(如此处的 N \times N 矩阵乘法),分解成一系列可以在高速缓存中完成的、更小的子任务。
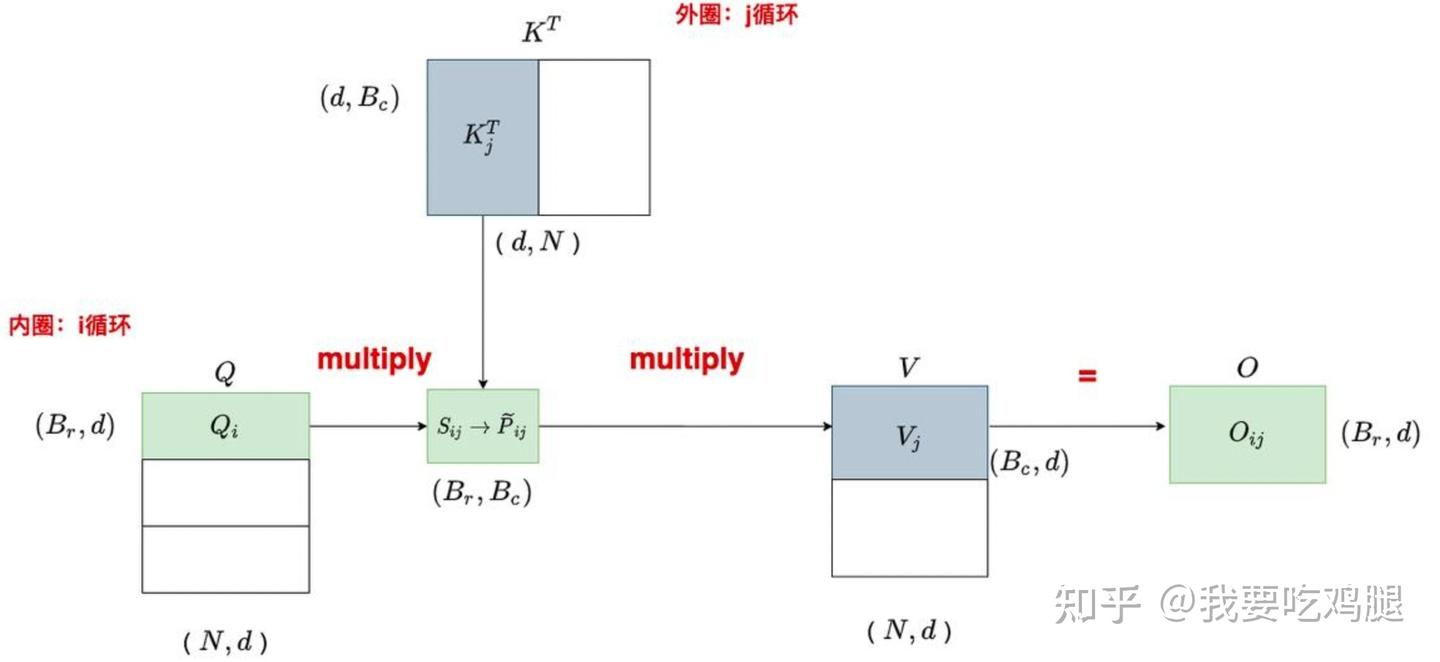
具体到 Flash Attention 中,Tiling 的应用如下: 1. 切分输入:将 Q, K, V 三个矩阵沿着序列长度 N 的维度,切分成若干个大小固定的块(Block)。例如,Q 被切分为多个 B_r \times d 的块,K 和 V 被切分为多个 B_c \times d 的块。
- 精心设计的块大小:块的大小 B_r 和 B_c 并非随意设定,而是根据 GPU 可用的 SRAM 容量上限 M 精心计算得出的。其目标是确保在一个计算步骤中,所需的所有输入数据块(例如一个 Q 块、一个 K 块、一个 V 块以及用于计算的中间结果)能够被完全加载到 SRAM 中。
根据 Flash Attention 论文中的设定,块大小的计算公式如下:
B_c = \lceil \frac{M}{4d} \rceil, \quad B_r = \min \left( \lceil \frac{M}{4d} \rceil, d \right)
这样设计的目的是为了确保 Q, K, V 各个块占用的 SRAM 空间总和不超过上限 M。我们可以大致分析一下所需的主要内存:
K 和 V 块:加载 K, V 的一个分块 K_j, V_j 需要的 SRAM 空间为
SRAM(K_j, V_j) = 2 \times B_c \times d = 2 \times \lceil \frac{M}{4d} \rceil \times d < \lceil \frac{M}{2} \rceil。根据 B_c 的公式,这部分空间小于 \frac{M}{2}。
Q 块:加载 Q 的一个分块 Q_i 需要的 SRAM 空间为 SRAM(Q_i) = B_r \times d = \min \left( \lceil \frac{M}{4d} \rceil, d \right) \times d < \lceil \frac{M}{4} \rceil,这部分空间小于 \frac{M}{4}。
O 块 (中间输出):用于存储中间计算结果的输出块 O_i 需要的空间也为
SRAM(O_i) = B_r \times d = \min \left( \lceil \frac{M}{4d} \rceil, d \right) \times d < \lceil \frac{M}{4} \rceil,同样小于 \frac{M}{4}。
将这几部分加起来,其空间占用严格小于 \lceil \frac{M}{2} \rceil + \lceil \frac{M}{4} \rceil + \lceil \frac{M}{4} \rceil。再加上用于存储 l_i, m_i 等统计量的额外少量空间,基本上就将 SRAM 的可用容量给打满了。通过这种精确的内存规划,Flash Attention 确保了其核心计算都可以在高速的片上内存中进行。
- 块间计算:算法通过内外两层循环来遍历这些块。如下图所示,在 V1 的设计中,外层循环遍历 K 和 V 的各个块(K_j^T, V_j),内层循环则遍历 Q 的各个块(Q_i)。在每次内外循环的交汇点,一个 Q 块和一个 K 块会在 SRAM 中进行计算,得到一个局部的注意力分数块 S_{ij},并与对应的 V 块进行聚合。
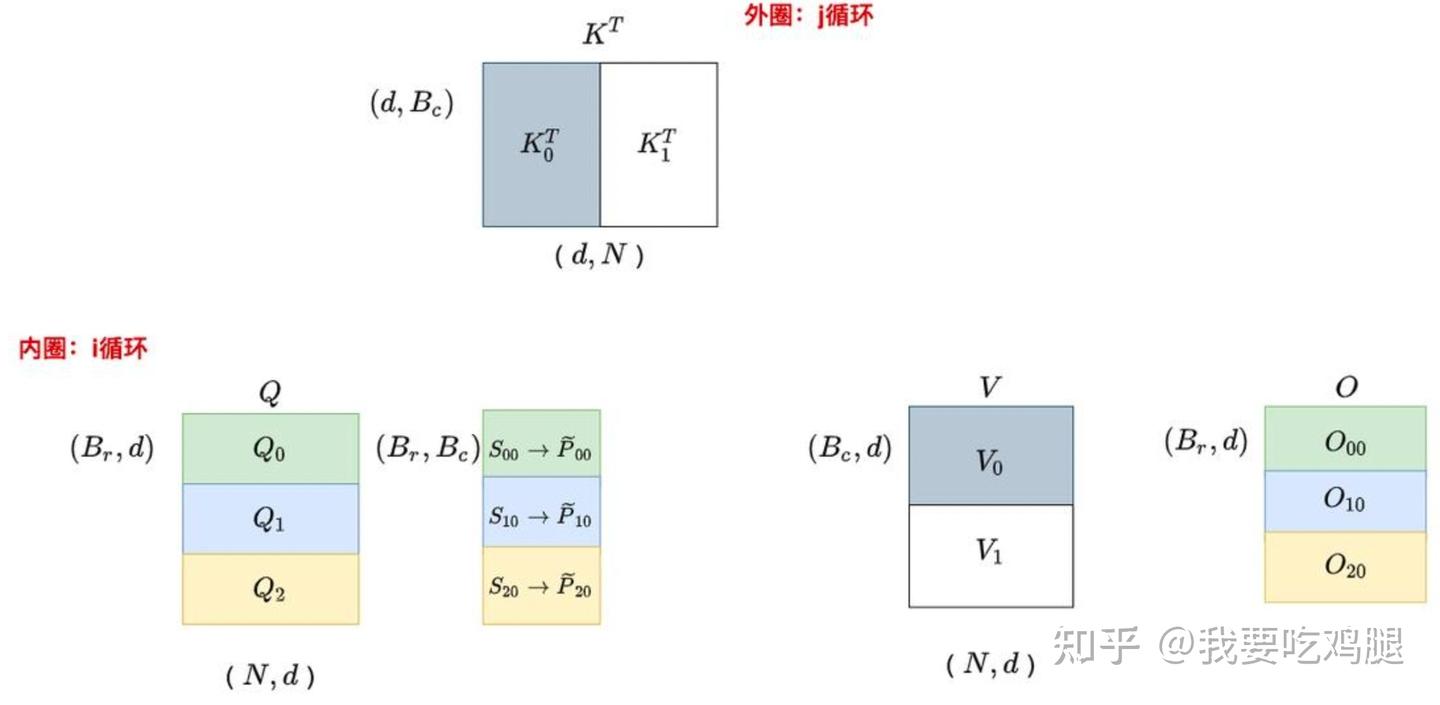
FlashAttention V1内外循环示意图
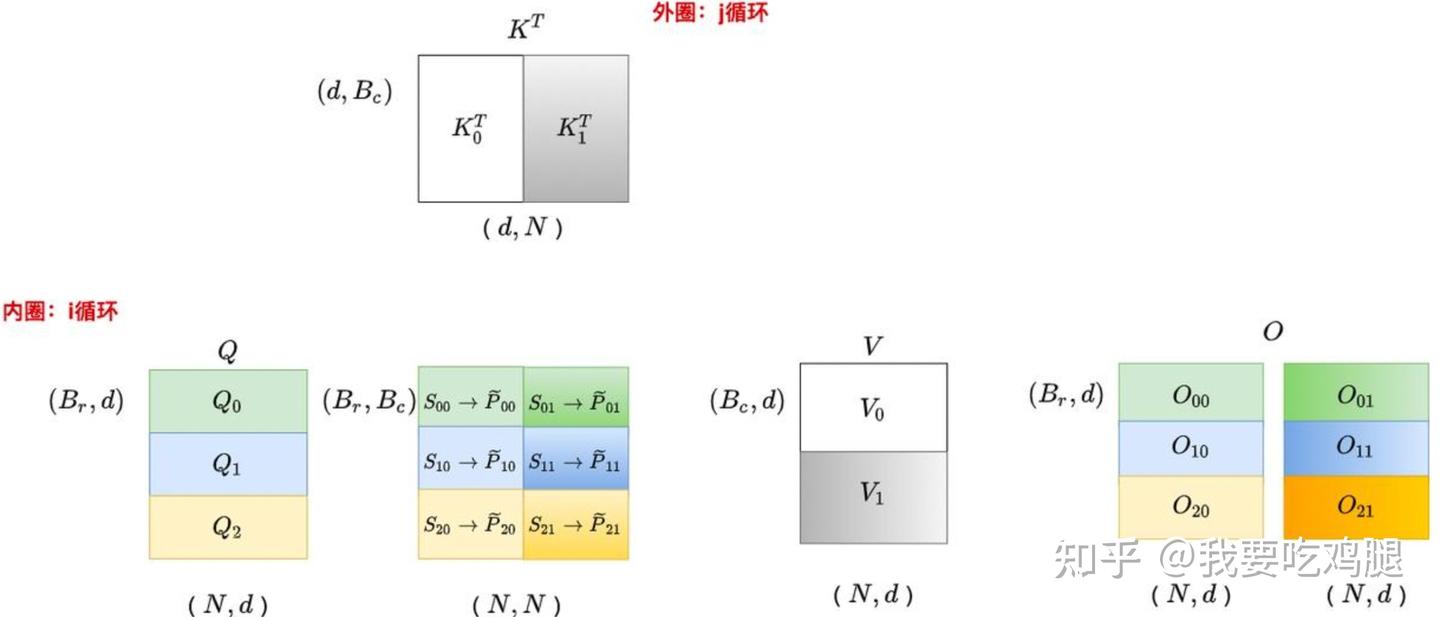
FlashAttention V1内外循环示意图
通过 Tiling,原本需要 O(N^2) 空间的巨大计算被分解为一系列可在 O(\text{BlockSize}^2) 空间内完成的“片上计算”(On-chip computation),从根本上避免了在 HBM 中实例化完整的 N \times N 矩阵。
2.1.2 Kernel Fusion (算子融合)
Tiling 为 Kernel Fusion 创造了完美的条件。一旦所需的数据块(Q_i, K_j, V_j)被加载到 SRAM 这个“高速工作台”上,我们就可以将原本分离的多个计算步骤,融合成一个单一的、连续的 GPU 计算任务(Kernel)。
上图中间部分生动地展示了这一过程:K 和 V 的一个块被从 HBM 拷贝(Copy) 到 SRAM 中。 随后,Q 的各个块被依次拷贝到 SRAM 中,与 SRAM 中已有的 K/V 块进行计算(Compute Block on SRAM)。 这个“计算”并非只是简单的矩阵乘法,而是包含了矩阵乘、Mask(可选)、Softmax、Dropout(可选)、再与 V 块相乘等一系列操作。 所有这些操作都在数据不离开 SRAM 的情况下“一气呵成”,计算出的部分结果 O_{ij} 被累加,直到内层循环结束,最终的输出块 O_i 才被写回 HBM。
Kernel Fusion 的威力在于,它将标准 Attention 中多次往返 HBM 的独立操作(见上图右侧 PyTorch 实现的分解),变成了一次 HBM 读(加载 Q, K, V 块) -> 一系列 SRAM 内部计算 -> 一次 HBM 写(写回 O 块)的高效流程。
2.1.3 算法总结
Tiling 和 Kernel Fusion 相辅相成,共同构成了 Flash Attention V1 的基石。Tiling 解决了“空间”问题,将大计算分解为 SRAM 可容纳的小计算;而 Kernel Fusion 解决了“时间”问题,将多个分散的 HBM 访问合并为少数几次,从而将算法的性能瓶颈从缓慢的内存 I/O,转移到了高效的 SRAM 内部计算上。
2.2 关键技术:Online Softmax 的演进与1-pass Attention的实现
Tiling 和 Kernel Fusion 为我们搭建了舞台,但要让这出戏成功上演,还必须解决最棘手的技术难题:如何在分块(局部)计算的模式下,得到一个需要全局信息的 Softmax 的精确结果?
Flash Attention 的解决方案并非一蹴而就,而是借鉴并极大地发展了在线 Softmax (Online Softmax) 的思想。这个思想的演进过程,正是从一个低效的“三趟式(pass)”计算,逐步优化到高效“单趟式(pass)”计算的核心路径。
2.2.1 从 3-pass 到 2-pass:在线 Softmax 的第一步
我们在 1.2 节中提到,朴素的 Safe Softmax 是一个需要三次遍历数据的 3-pass 算法。问题出在第二次遍历(计算分母 l_i)时,它依赖于第一次遍历算出的最终全局最大值 m_N。
l_i \leftarrow l_{i-1} + e^{x_i – m_N} 这个对最终结果 m_N 的依赖,使得计算 m 和计算 l 的过程无法被合并。
然而,数学家们发现,通过一个巧妙的公式变换,我们可以构建一个不依赖于最终全局最大值 m_N 的递归关系。我们定义一个新的中间变量 l’:
l’_i := \sum_{j=1}^i e^{x_j – m_i} 这里的关键区别在于,求和的每一项减去的是到当前步为止的最大值 m_i,而不是最终的 m_N。基于这个定义,可以推导出 l’_i 与 l’_{i-1} 之间的递归关系:
l’_i = l’_{i-1} e^{m_{i-1} – m_i} + e^{x_i – m_i} 这个公式的绝妙之处在于,计算当前的 l’_i 只依赖于上一步的 l’_{i-1}、m_{i-1} 以及当前步的 m_i 和 x_i,完全摆脱了对未来的全局值 m_N 的依赖。
这样一来,我们就可以将寻找最大值和计算(修正后的)分母这两个步骤合并到同一个循环中,从而将原始的 3-pass 算法优化为了 2-pass online softmax。第一趟循环同时计算出 m_N 和 l’_N(当 i=N 时,l’_N 就等于我们想要的最终分母 l_N),第二趟循环则利用这两个值计算最终的概率,算法的具体流程如下:
Algorithm 2-pass online softmax
for i ← 1, N do m_i \leftarrow \max(m_{i-1}, x_i)
l’_i \leftarrow l’_{i-1} e^{m_{i-1}-m_i} + e^{x_i – m_i}
end
for i ← 1, N do P_i \leftarrow \frac{e^{x_i – m_N}}{l’_N}
end
2.2.2 从 2-pass Attention 到 1-pass Attention 的飞跃
这个 2-pass 的在线 Softmax 思想可以直接应用于 Attention 计算,但这并不能一步到位地解决问题。如下图所示,如果我们直接套用,会得到一个“多趟自注意力(Multi-pass Self-Attention)”算法:
Algorithm Multi-pass Self-Attention
Notations
Q[k,:]: the k-th row vector of Q matrix.
K^T[:, i]: the i-th column vector of K^T matrix.
O[k,:]: the k-th row of output O matrix.
V[i,:]: the i-th row of V matrix.
\{o_i\}: \sum_{j=1}^i P_j\, V[j,:], a row vector storing partial aggregation result A[k,:i]\times V[:i,:].
Body
for i ← 1, N do x_i \leftarrow Q[k,:]\, K^T[:, i]
m_i \leftarrow \max(m_{i-1},\, x_i)
l’_i \leftarrow l’_{i-1}\, e^{m_{i-1}-m_i} + e^{x_i – m_i}
end
for i ← 1, N do P_i \leftarrow \frac{e^{x_i – m_N}}{l’_N}
o_i \leftarrow o_{i-1} + P_i\, V[i,:]
end O[k,:] \leftarrow o_N
这个算法依然是两趟式(two pass)的:
- 第一趟循环:遍历 K/V,在线计算出 x_i(即 Q[k,:] K^T[:,i]),并同时完成Online Softmax 的第一步,得到最终的 m_N 和 l’_N。
- 第二趟循环:再次遍历 K/V,计算每个位置的最终概率 P_i,然后乘以对应的 V[i,:],并累加得到最终的输出 o_i。
问题在于,计算输出 o_i 的步骤(o_i \leftarrow o_{i-1} + P_i V[i,:])依赖于最终的概率 P_i,而 P_i 又依赖于第一趟循环算完才能知道的 m_N 和 l’_N。这使得输出的计算无法被合并到第一个循环中。
2.2.3 Flash Attention 的终极突破:1-pass 实现
Flash Attention 的作者在这里提出了一个革命性的洞见:既然我们的最终目标是输出 O,而非中间的概率矩阵 P,那么我们是否可以像推导 l’ 那样,也为输出 O 构建一个不依赖于最终全局统计量(m_N, l_N)的在线更新公式呢?
答案是肯定的。作者定义了这样一个新的输出变量 o’:
o’_i := \sum_{j=1}^{i} \frac{e^{x_j – m_i}}{l’_i} V[j,:] 同样,这个 o’_i 的计算只依赖到当前步 i 为止的统计量 m_i 和 l’_i。经过一系列精妙的数学推导,得到了 o’_i 和 o’_{i-1} 之间的递归关系:
\begin{aligned} o_i’ &= \sum_{j=1}^{i} \frac{e^{x_j – m_i}}{l_i’} V[j,:] \\[6pt] &= \left( \sum_{j=1}^{i-1} \frac{e^{x_j – m_i}}{l_i’} V[j,:] \right) + \frac{e^{x_i – m_i}}{l_i’} V[i,:] \\[6pt] &= \left( \sum_{j=1}^{i-1} \frac{e^{x_j – m_{i-1}}}{l_{i-1}’} \cdot \frac{e^{x_j – m_i}}{e^{x_j – m_{i-1}}} \cdot \frac{l_{i-1}’}{l_i’} V[j,:] \right) + \frac{e^{x_i – m_i}}{l_i’} V[i,:] \\[6pt] &= \left( \sum_{j=1}^{i-1} \frac{e^{x_j – m_{i-1}}}{l_{i-1}’} V[j,:] \right) \cdot \frac{l_{i-1}’}{l_i’} e^{m_{i-1} – m_i} + \frac{e^{x_i – m_i}}{l_i’} V[i,:] \\[6pt] &= o_{i-1}’ \cdot \frac{l_{i-1}’}{l_i’} e^{m_{i-1} – m_i} + \frac{e^{x_i – m_i}}{l_i’} V[i,:] \end{aligned}
[FlashAttention 1-pass 算法]
Algorithm FlashAttention
for i ← 1, N do
x_i \leftarrow Q[k,:]\, K^T[:, i]
m_i \leftarrow \max(m_{i-1}, x_i)
l’_i \leftarrow l’_{i-1} e^{m_{i-1}-m_i} + e^{x_i – m_i}
o’_i \leftarrow o’_{i-1} \frac{l’_{i-1}}{l’_i} e^{m_{i-1}-m_i} + \frac{e^{x_i – m_i}}{l’_i} V[i,:]
end
O[k,:] \leftarrow o’_N 这个公式是 Flash Attention V1 的灵魂。它表明,我们可以在同一个循环中,与更新 m_i 和 l’_i 同步地、在线地更新输出 o’_i。每一个新元素 x_i 到来时,我们不仅更新统计量,还用它来修正(rescale)已经算好的 o’_{i-1},并叠加上当前元素带来的新贡献。
通过这个一体化的更新公式,Flash Attention 成功地将 Attention 的所有计算——包括 QK^T 的点积、在线 Softmax 以及与 V 的加权求和——全部融合到了一个单趟的(1-pass)循环中。这彻底消除了对 HBM 的中间结果读写,是其实现高性能的关键所在。
2.2.4 Tiling 下的算法实现
上一部分我们推导出了 Flash Attention 的核心“单趟式(1-pass)”更新公式。现在,我们来看这个思想在 Tiling 模式下是如何具体实现的。算法的核心逻辑被封装在一个嵌套循环中:外层循环遍历 K 和 V 的块,内层循环遍历 Q 的块。

FlashAttention V1 算法伪代码
结合上面的完整伪代码,我们可以将内层循环中的一次迭代(即处理一个 Q_i 块和 K_j 块)分解为以下几个关键步骤:
-
Step 1: 从 HBM 加载数据 (Load)
-
算法首先从慢速的 HBM 中,将当前外层循环对应的 K_j 和 V_j 块,以及当前内层循环对应的 Q_i 块加载到高速的 SRAM 中。
-
同时,与 Q_i 块对应的、记录着到上一个外层循环为止的统计总和的 l_i 和 m_i,以及中间输出 O_i,也会被一并加载进来。
-
Step 2: 片上计算局部注意力 (On-chip Compute)
-
在 SRAM 内部,用加载进来的 Q_i 和 K_j 计算局部的分数矩阵 S_{ij} = Q_i K_j^T。
-
紧接着,对 S_{ij} 进行局部的 Safe Softmax 操作:找到当前块每行的最大值 \tilde{m}_{ij},计算出 \tilde{P}_{ij} = \exp(S_{ij} – \tilde{m}_{ij}),并求和得到局部的分母 \tilde{l}_{ij}。注意,到这一步为止,所有的计算都局限于当前块,未使用任何全局信息。
-
Step 3: 在线更新全局统计量 (Online Update)
-
这是算法最核心的一步。算法会使用当前块的局部最大值 \tilde{m}_{ij} 和历史全局最大值 m_i,来计算出新的全局最大值 m_i^{\text{new}} = \max(m_i, \tilde{m}_{ij})。
-
然后,利用新旧全局最大值,对历史分母 l_i 和当前块的局部分母 \tilde{l}_{ij} 进行缩放(rescale)和合并,得到新的全局分母 l_i^{\text{new}}:l_i^{\text{new}} = e^{m_i – m_i^{\text{new}}} l_i + e^{\tilde{m}_{ij} – m_i^{\text{new}}} \tilde{l}_{ij}
-
Step 4: 在线更新输出并写回 HBM (Update and Write back)
-
与更新分母的逻辑完全类似,算法也会对历史输出 O_i 进行缩放,并叠加上当前块计算出的局部输出(\tilde{P}_{ij}V_j),得到新的全局输出 O_i: O_i \leftarrow \text{diag}((l_i^{\text{new}})^{-1}) \left( \text{diag}(l_i)e^{m_i – m_i^{\text{new}}} O_i + e^{\tilde{m}_{ij} – m_i^{\text{new}}} \tilde{P}_{ij} V_j \right)
-
计算完成后,更新后的 O_i, l_i, m_i 会被写回 HBM,等待下一个外层循环的迭代。当外层循环(即遍历完所有 K/V 块)结束后,HBM 中存储的 O_i 就是最终的、精确的注意力输出结果。
2.2.5 图解在线更新机制
为了更直观地理解这个在线更新的过程,我们可以看下图的分解:
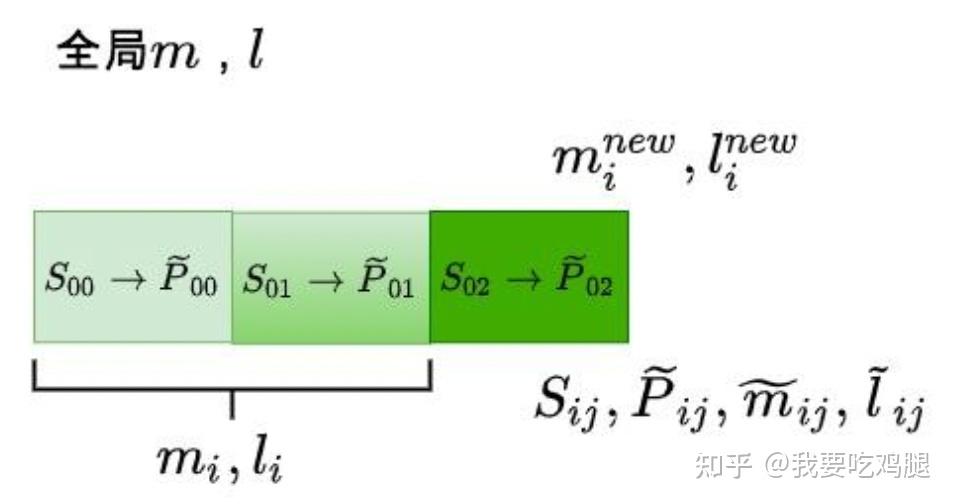
假设我们正在为 Q 的某一行计算输出,并且已经处理完了前两个 K/V 块(S_{00}, S_{01})。此时,我们在内存中记录了到目前为止的全局统计量 m_i, l_i。
现在,我们加载了第三个 K/V 块,并在 SRAM 中计算出了它的局部统计量 S_{i2}, \tilde{P}_{i2}, \tilde{m}_{i2}, \tilde{l}_{i2}。在线更新机制的核心就是利用这些历史信息和当前信息,通过上述的缩放和合并公式,计算出包含前三个块信息的、全新的全局统计量 m_i^{\text{new}}, l_i^{\text{new}}。对输出 O_i 的更新也是同理。
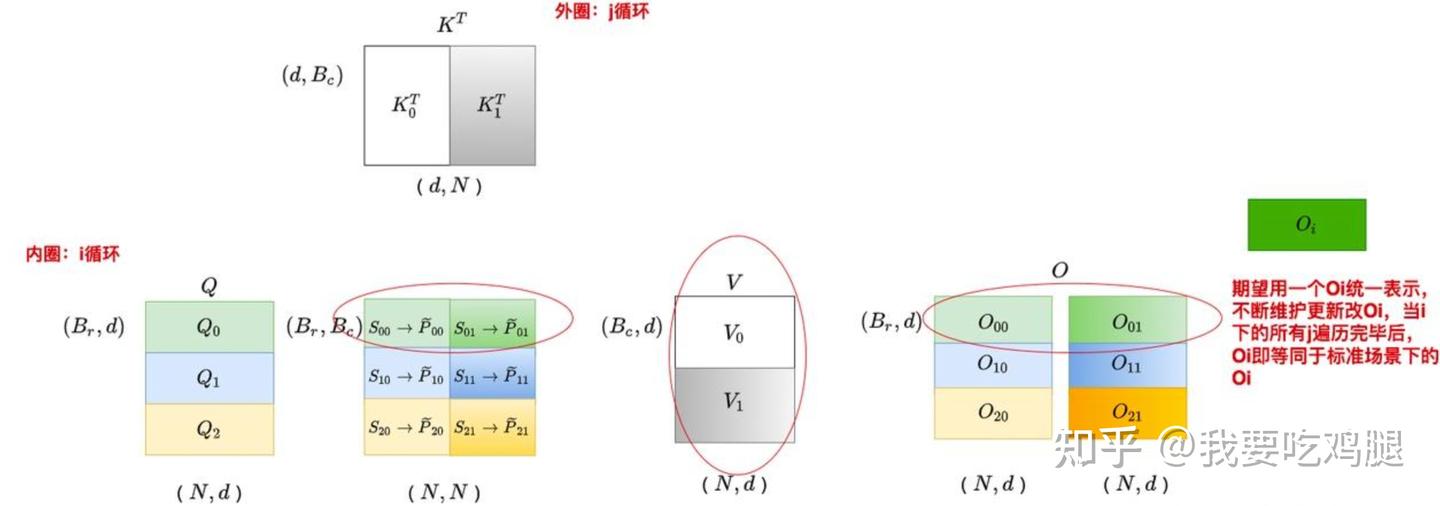
上图更宏观地展示了整个流程。对于 Q 的每一个分块(如 Q_0, Q_1, Q_2),都对应一个不断被迭代更新的输出块(O_0, O_1, O_2)。随着外层循环(K_0^T \rightarrow K_1^T)的推进,每一个 O_i 块都会被反复从 HBM 中读出,与新的 K/V 块计算出的局部结果进行融合,然后写回。当外层循环遍历完毕后,HBM 中存储的 O 矩阵就等于标准 Attention 在非分块场景下计算出的最终结果。
正是通过这种精妙的、带有 rescaling 的迭代式更新算法,Flash Attention V1 在保证计算结果完全精确的前提下,成功地将计算过程分解到了 SRAM 可容纳的小块上,实现了革命性的性能优化。
2.3 V1 理论分析与实验验证
2.3.1 计算量 (FLOPs) 分析
在深入显存和 I/O 复杂度的革命性优化之前,我们首先需要回答一个关键问题:Flash Attention 是否通过减少计算量(即浮点运算次数 FLOPs)来实现加速的?
要分析算法的计算量,我们首先需要明确如何估算其中占大头的矩阵乘法操作。
当我们将一个 M \times K 的矩阵与一个 K \times N 的矩阵相乘时,为了得到结果矩阵(大小为 M \times N)中的一个元素,我们需要进行 K 次乘法运算和 K-1 次加法运算。结果矩阵共有 M \times N 个元素,因此总的浮点运算次数约为 M \times N \times (2K – 1)。在大 O 表示法中,我们通常忽略低阶项和常数,并将其近似为 2 \times M \times K \times N FLOPs。
Flash Attention V1 计算量分析
现在,我们用这个方法来分析 Flash Attention V1 算法(参考下图伪代码)的核心计算步骤:

- 计算 S_{ij} = Q_i K_j^T
- 这一步发生在内层循环中。
- 涉及的矩阵大小为:Q_i \in \mathbb{R}^{B_r \times d} 和 K_j^T \in \mathbb{R}^{d \times B_c}。
- 对应到 M \times K \times N 的范式,这里 M=B_r, K=d, N=B_c。
- 因此,这一步的计算量为 O(B_r \cdot d \cdot B_c)。
2. 计算 \tilde{P}_{ij} V_j
- 这一步也发生在内层循环中,是更新输出 O_i 的一部分。
- 涉及的矩阵大小为:\tilde{P}_{ij} \in \mathbb{R}^{B_r \times B_c} 和 V_j \in \mathbb{R}^{B_c \times d}。
- 对应到 M \times K \times N 的范式,这里 M=B_r, K=B_c, N=d。
- 这一步的计算量同样为 O(B_r \cdot B_c \cdot d)。
总计算量
算法的内外层循环总共会执行 T_r \times T_c 次,其中 T_r = N_{seq}/B_r,T_c = N_{seq}/B_c(这里用 N_{seq} 代表序列长度以区分范式中的 N)。
因此,Flash Attention V1 的总计算量(仅考虑主要的矩阵乘法)可以估算为:
\text{Total FLOPs} \approx (T_r \times T_c) \times (O(B_r d B_c) + O(B_r B_c d)) = (\frac{N_{seq}}{B_r} \times \frac{N_{seq}}{B_c}) \times O(B_r d B_c) = O(N_{seq}^2 d)
结论
这个 O(N_{seq}^2 d) 的结果与标准 Attention 的计算量在同一个数量级。实际上,由于Online Softmax 过程中引入了一些额外的逐元素缩放操作,Flash Attention 的总 FLOPs 甚至会比标准 Attention 略高一些。
这就得出了本小节最关键的结论:Flash Attention 并没有减少总的浮点运算次数,它的惊人加速并非来自“少算了”,而是来自对计算方式的重构,从而优化了其他更重要的性能瓶颈。
2.3.2 显存占用 (Memory) 分析
上一节我们得出结论,Flash Attention 的加速并非来自计算量的减少。那么,它的第一个巨大优势体现在哪里呢?答案是显存占用。
标准 Attention 的显存瓶颈
正如我们在第一章中反复强调的,标准 Attention 的朴素实现有一个致命的缺陷:它需要在 HBM 中显式地创建并存储两个巨大的中间矩阵。
- 分数矩阵 S: 通过 S = QK^T 计算得出,其维度为 N \times N。
- 概率矩阵 P: 通过 P = \text{softmax}(S) 计算得出,其维度同样为 N \times N。
这两大矩阵的内存占用都与序列长度 N 的平方成正比。因此,标准 Attention 对 HBM 的内存占用复杂度为:
\text{Memory}_{\text{standard}} = O(N^2) 这个 O(N^2) 的增长是极其恐怖的。当序列长度翻倍时,显存占用会变成原来的四倍。这直接导致了在硬件显存有限的情况下,模型能够处理的序列长度受到了严格的限制。
例如,对于一个拥有 128 个头的模型,在 fp16 精度下,当序列长度达到 128k 时,仅存储 P 矩阵就需要 128 \times (128k \times 128k) \times 2 \text{ bytes} \approx 4 \text{TB} 的显存,这远远超出了任何单张 GPU 的容量。
Flash Attention 的显存优化
Flash Attention 通过其核心的 Tiling 和在线更新机制,从根本上解决了这个问题。
- Tiling 避免了全局矩阵的创建:由于计算被分解到 SRAM 可容纳的小块上进行,算法自始至终都不需要在 HBM 中创建和存储完整的 N \times N 的 S 和 P 矩阵。局部的分数块 S_{ij} 和概率块 \tilde{P}_{ij} 都是在 SRAM 中临时创建、使用后立即被丢弃的“中间产物”。
- 在线更新机制仅需少量额外存储:为了实现精确的在线更新,算法确实需要一些额外的存储空间来记录每个 Q 块(大小为 B_r)对应的统计量,即 m_i(行最大值)和 l_i(行分母)。这两个统计量的总大小与序列长度 N 成正比,为 O(N)。
因此,Flash Attention 在计算过程中,除了输入(Q, K, V)和最终输出(O)之外,几乎没有其他大规模的显存开销。其额外内存占用复杂度为: \text{Memory}_{\text{flash}} = O(N)
结论
通过将内存占用从二次方级别(O(N^2))降低到线性级别(O(N)),Flash Attention 极大地节省了显存。这不仅意味着在相同的硬件上可以处理更长的序列,也为在训练和推理过程中节省了大量的内存管理开销,是其相比标准 Attention 的第一个革命性优势。
2.3.3 I/O 复杂度 (HBM Accesses) 分析
我们在 2.3.1 节中证明了 Flash Attention 并没有减少计算量,在 2.3.2 节中阐明了它如何节省显存。现在,我们来分析其性能提升的直接原因——对 HBM I/O 复杂度的革命性优化。
标准 Attention 的 I/O 瓶颈回顾
如 1.2 节所分析,标准 Attention 的“三趟式”计算流程决定了其大量的 HBM 读写操作。每一次 Pass 都需要将数据完整地从 HBM 读入,计算后再写回 HBM。这个过程涉及对 Q, K, V, S, P 矩阵的多次完整读写,导致其总的 I/O 复杂度高达: \text{I/O}_{\text{standard}} = O(Nd + N^2)
当序列长度 N 很大时,N^2 项占据主导地位,I/O 开销变得极为庞大,牢牢地限制了算法的整体性能。
Flash Attention V1 的 I/O 行为分析
现在,我们来仔细剖析 Flash Attention V1 算法(参考上图伪代码)的 HBM 访问模式:
- 外层循环:加载 K 和 V
- 算法的外层循环会遍历 K 和 V 的所有分块,共 T_c = N/B_c 次。
- 在每一次外层循环中,一个 K 块和一个 V 块被加载到 SRAM。
- 因此,在整个算法执行完毕后,完整的 K 矩阵和 V 矩阵都恰好被从 HBM 中读取了一遍。这部分的 I/O 开销为 O(Nd)。
2. 内层循环:加载 Q 并读写 O
-
算法的内层循环会遍历 Q 的所有分块,共 T_r = N/B_r 次。
-
关键在于,这个内层循环是嵌套在外层循环里的。这意味着,对于外层循环的每一次迭代,内层循环都会把整个 Q 矩阵和 O 矩阵完整地过一遍。
-
具体来说,对于外层循环的第 j 次迭代(加载了 K_j, V_j),算法会:
-
完整地从 HBM 读取一遍 Q 矩阵(块 by 块)。
-
完整地从 HBM 读取一遍 O 矩阵(用于更新)。
-
完整地将更新后的 O 矩阵写回 HBM。
-
由于外层循环有 T_c 次,因此对 Q 和 O 的总 I/O 操作次数被放大了 T_c 倍。这部分的主要 I/O 开销为 O(T_c \cdot Nd)。
I/O 复杂度推导
综合以上两点,Flash Attention V1 的总 I/O 复杂度近似为:
\text{I/O}_{\text{flash}} \approx O(Nd) + O(T_c \cdot Nd) = O(\frac{N}{B_c} \cdot Nd) 我们知道,块大小 B_c 是由 SRAM 容量 M 和头维度 d 决定的,B_c \approx \frac{M}{4d}。将其代入上式,我们得到:
\text{I/O}_{\text{flash}} \approx O(\frac{N}{M/4d} \cdot Nd) = O(\frac{N^2 d^2}{M})
注意:这是一个近似推导,更精确的分析会包含更多项,但数量级是正确的。*
结论:从 O(N^2) 到 O(\frac{N^2 d^2}{M}) 的飞跃
现在,我们可以清晰地对比两者的 I/O 复杂度了:
- 标准 Attention: O(Nd + N^2)
- Flash Attention: O(\frac{N^2 d^2}{M})
这个对比揭示了 Flash Attention 加速的本质:
它通过利用 SRAM,成功地将 I/O 复杂度中的 N^2 项与一个分母 M (SRAM 容量) 关联了起来。由于 M 是一个与 N 无关的硬件参数,并且通常远大于 d^2,Flash Attention 相当于将 I/O 开销降低了 M/d^2 倍。
例如,对于 N=2k, d=256, M=192KB 的情况,标准 Attention 的 I/O 访问量约为 4.7M Bytes,而 Flash Attention 约为 1.4M Bytes。虽然两者都是 N^2 级别,但 Flash Attention 的常数因子要小得多。
关键洞察:Flash Attention 并没有消除 I/O 对 N^2 的依赖,但它通过引入硬件参数 M 作为分母,极大地降低了 I/O 访问的绝对数量。这正是其“IO-Awareness”思想的体现:算法的设计与硬件的特性(SRAM容量)深度绑定,从而将一个原本被 HBM 带宽限制死的问题,转化为了一个可以在 SRAM 内部高效解决的问题。 这就是它能实现数倍加速的根本原因。
2.3.4 实验数据验证与 Block Size 的影响
经过前面三个小节对计算量、显存和 I/O 复杂度的理论剖析,我们已经从原理上理解了 Flash Attention V1 的优势所在。现在,我们用实验数据来直观地验证这些结论。
性能数据验证
Flash Attention 论文中的实验结果为我们提供了强有力的证据。

Flash Attention 性能对比图
上图左侧的表格清晰地展示了在 GPT-2 模型上,标准 Attention 与 Flash Attention 在一次前向+反向传播过程中的性能对比:
- GFLOPs (计算量): 标准 Attention 为 66.6 GFLOPs,而 Flash Attention 为 75.2 GFLOPs。这有力地印证了我们在 2.3.1 节的结论:Flash Attention 并没有减少计算量,甚至略有增加。
- HBM R/W (I/O): 这是差异最悬殊的一项。标准 Attention 需要 40.3 GB 的 HBM 读写量,而 Flash Attention 仅需要 4.4 GB,I/O 量降低了近 90%。这完美地验证了我们在 2.3.3 节的分析,即 Flash Attention 的核心优势在于革命性地减少了对 HBM 的访问。
- Runtime (运行时间): 最终的性能表现是前两者的综合结果。尽管计算量略有增加,但由于 I/O 瓶颈被彻底打破,Flash Attention 的总运行时间从 41.7ms 缩短到了 7.3ms,实现了约 5.7 倍的端到端加速。
Block Size 的影响
Tiling 的核心参数是块的大小(Block Size),即 B_r 和 B_c,它的选择直接影响算法性能。上图中间的图表展示了 Block Size 对 HBM 访问量和运行时间的影响:
- 趋势: 随着 Block Size 从 64 增加到 256,我们可以看到 HBM Accesses 和 Runtime 都在迅速下降。这是因为更大的 Block Size 意味着每次从 HBM 加载的数据块更大,数据在 SRAM 中的复用率更高,从而减少了总的加载次数。
- 平台期: 当 Block Size 达到 256 之后,性能曲线趋于平缓。这通常意味着此时的性能瓶颈已经从 HBM I/O 转移到了其他方面,例如 SRAM 的容量上限被占满,或者计算单元本身达到了饱和。继续增大 Block Size 不再能带来显著的 I/O 收益。
Block Size 与 headdim=d 的深层关系
更进一步地,Block Size 的选择并非孤立的,它与模型的头维度 headdim=d 密切相关。根据我们在 2.1 节中讨论的公式,B_r 和 B_c 的大小与 d 成反比。这意味着,当模型的 headdim=d 越大时,为了将计算块放入有限的 SRAM 中,Block Size 就必须越小。
而更小的 Block Size 会从两个方面导致运行时间(Runtime)增加:
- 需要更多的 Thread Block 和调度开销:由于每个 thread block 能处理的数据量有限(由 SRAM 容量限制),当 d 增大导致 Block Size 减小时,处理同样长度的序列(seqlen)就需要遍历更多的次数,即需要启动和调度更多的 thread block。在 GPU SM 占用率(occupancy)相同的情况下,更多的调度次数自然会导致耗时增加。
- 增加总的 Memory Accesses:这一点在 Flash Attention V2 的内外循环设计(外 Q 内 K/V)中尤为明显。由于 B_r 变小,意味着外层 Q 循环的次数变多了。对于每一次 Q 的循环,都需要将完整的 K 和 V 矩阵分块加载到 SRAM 中过一遍。因此,外层循环次数的增加,直接导致了总的 Memory Accesses 增加,从而增加了运行耗时。
I/O 复杂度的临界点
我们在 2.3.3 节推导出 Flash Attention 的 I/O 复杂度约为 O(\frac{N^2 d^2}{M})。这表明 Memory Accesses 和 d 的平方成正比关系。当 d 变得非常大时,Flash Attention 的 I/O 优势会急剧减小,甚至可能反超标准 Attention,咱们在前面已经计算过了两种情况的IO复杂度:
- 标准 Attention: O(Nd + N^2)
- Flash Attention: O(\frac{N^2 d^2}{M})
这边给大家举几个计算实例:
当 N=2k, M=192KB, d=256 时:
Naive Attention I/O = 2048*256 + 2048*2048 = 4718592 ≈ 4.7M
Flash Attention I/O = 2048*2048*256*256/(192*1024) = 1398101.3333333333 ≈ 1.4M
此时,FA IO Accesses < Naive Attention IO Accesses,Flash Attention 具有明显的 I/O 优势。
当 N=2k, M=192KB, d=512 时:
Naive Attention I/O = 2048*512 + 2048*2048 = 5242880 ≈ 5.2M
Flash Attention I/O = 2048*2048*512*512/(192*1024) = 5592405.333333333 ≈ 5.6M
此时,FA IO Accesses > Naive Attention IO Accesses,Flash Attention 的 I/O 优势已经不复存在。
在这种情况下(d 非常大),Flash Attention 无论是在 I/O 还是在 FLOPs(本身就略高)上都已不占优势。其唯一剩下的优点,就只有节省显存(不需要存储 N \times N 的中间矩阵)了。
这个分析深刻地揭示了 Flash Attention 并非在所有情况下都是最优的,它的性能与模型的具体参数(尤其是 headdim)和硬件的 SRAM 容量密切相关,体现了算法与硬件协同设计的复杂性和重要性。
这个图表直观地体现了 Tiling 优化的效果,并说明了选择一个合适的、与硬件(SRAM 容量)相匹配的 Block Size 对于发挥 Flash Attention 的最大性能至关重要。
至此,我们完成了对 Flash Attention V1 的全面剖析。它通过 Tiling 和 Kernel Fusion 这两大核心思想,以及精妙的Online Softmax 更新算法,在不牺牲任何精度的情况下,将一个内存限制问题成功转化为了计算限制问题,从而在理论和实践上都取得了巨大的成功。
三、Flash Attention V2:追求极致的工程优化
Flash Attention V1 通过 Tiling 和在线 Softmax 算法,成功地解决了标准 Attention 的显存和 I/O 瓶颈,奠定了革命性的基础。然而,V1 的设计在某些场景下仍然存在性能瓶颈,未能将 GPU 的硬件潜力压榨到极致。Flash Attention V2 的诞生,正是在 V1 的核心思想之上,进行了一系列精妙的工程优化,旨在追求极致的性能和硬件利用率。
3.1 V1 的并行策略与局限
要理解 V2 的改进,我们首先需要剖析 V1 是如何组织并行计算的。在 GPU 编程中,一个大的计算任务通常被分解成许多独立的线程块(Thread Blocks),这些线程块会被 GPU 的调度器分发到不同的 SM(流多处理器)上并行执行。
Flash Attention V1 的并行策略非常直观:它在 batch_size 和 num_heads 这两个天然独立的维度上进行任务划分。
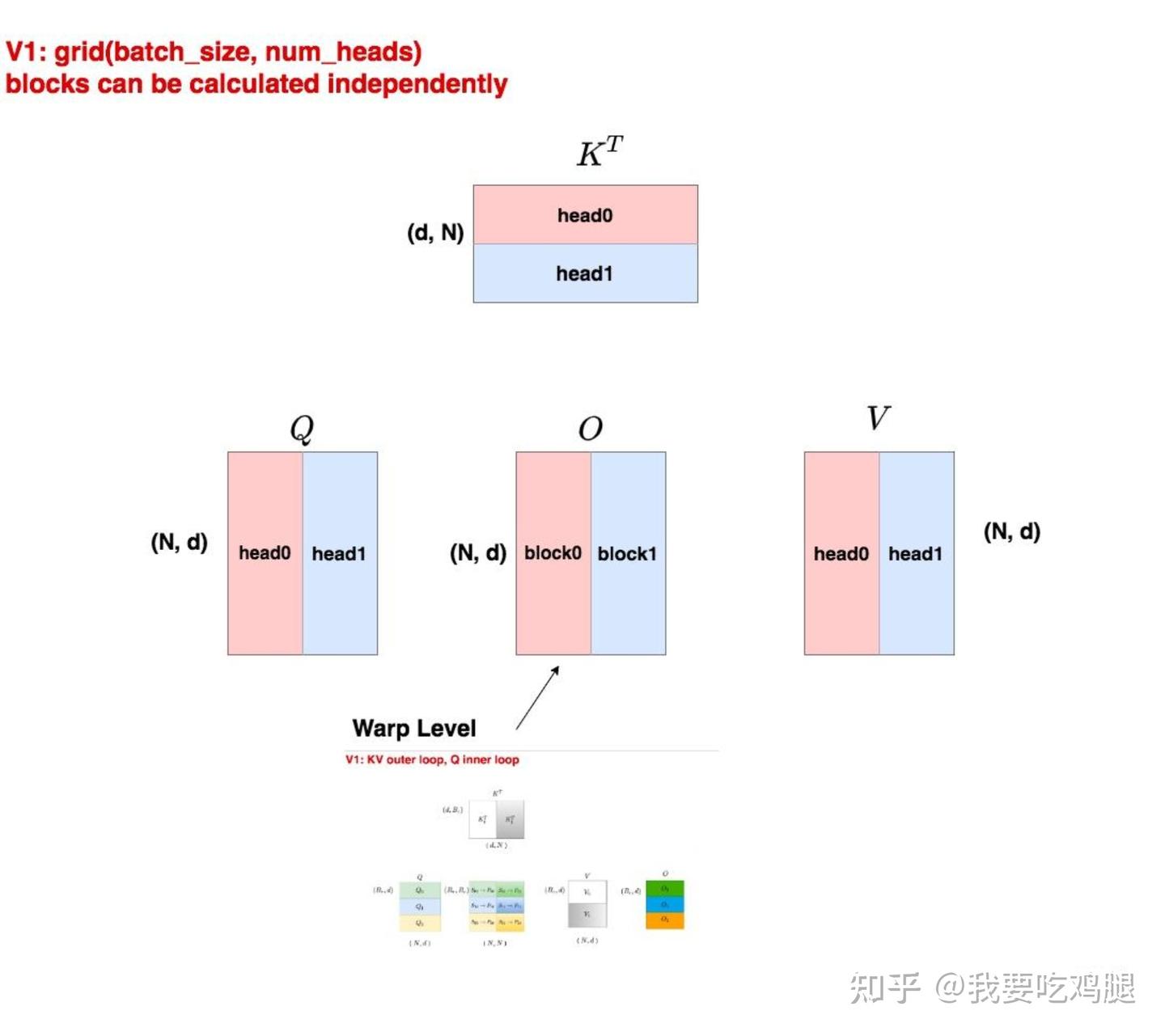
上图清晰地展示了 V1 的并行模式:
- Grid 划分: 启动的线程块网格(Grid)大小为
(batch_size, num_heads)。 - 任务分配: 这意味着,总共会启动
batch_size * num_heads个线程块。其中,每一个线程块都独立地、完整地负责计算**一个批次中的一项(one item in the batch)的一个头(one head)**的全部注意力操作。例如,block0负责计算batch item 0的head0,block1负责计算batch item 0的head1,以此类推。 - 数据独立性: 由于多头注意力机制中各个头的计算是完全独立的,因此这种划分方式确保了线程块之间不需要任何通信,可以高效地并行执行(V1 的“无通信”:指的是不同 Head 和 Batch 之间的独立性,V2 的“无通信”:指的是在单一 Head 内部,实现了序列维度的独立性,这里不要搞混了)。
V1 策略的局限性
这种并行策略虽然简单有效,但在某些常见场景下会暴露其明显的局限性:GPU 利用率不足。
现代的高性能 GPU(如 A100)拥有大量的 SM(例如 108 个)。为了让 GPU “火力全开”,我们需要创建足够多的线程块来让所有的 SM 都保持忙碌状态。
然而,V1 的线程块总数完全取决于 batch_size * num_heads。考虑以下场景:
当我们需要处理非常长的序列时(例如 32k tokens),由于显存的限制,我们不得不将 batch_size 设置得非常小(例如 1 或 2)。 同时,模型的 num_heads 也是一个固定的、通常不会太大的值(例如 8 或 12)。
在这种**“长序列,小批量”的场景下,总的线程块数量可能只有 1 * 8 = 8 个。这 8 个线程块被分发到拥有 108 个 SM 的 A100 GPU 上,意味着将有 100 个 SM 处于空闲状态**,造成了巨大的硬件资源浪费。这种低 GPU 占用率(Occupancy)问题,正是 V1 在处理长上下文任务时性能未能达到最优的根本原因。
正是为了解决这一局限,Flash Attention V2 对并行策略进行了核心的改进。
3.2 V2 的核心改进
针对 V1 在“长序列,小批量”场景下 GPU 利用率不足的问题,Flash Attention V2 引入了一系列深刻而高效的工程优化。这些改进并非对核心算法的颠覆,而是对计算流程、并行策略和底层实现的精妙重构,旨在将硬件性能压榨到极致。我们将分三部分来详细解析。
3.2.1 改进一:循环重排与序列维度并行
V2 的第一个、也是最核心的改进,是通过增加序列维度并行和重排内外循环这两项协同操作,从根本上解决了 V1 的并行度瓶颈,并进一步减少了 HBM I/O。
增加序列维度并行 (Sequence-Length Parallelism)
为了在任何场景下都能创建足够多的线程块来打满 GPU,V2 在 V1原有的 batch 和 head 维度之外,新增了在序列长度(Q 的行)维度上的并行。
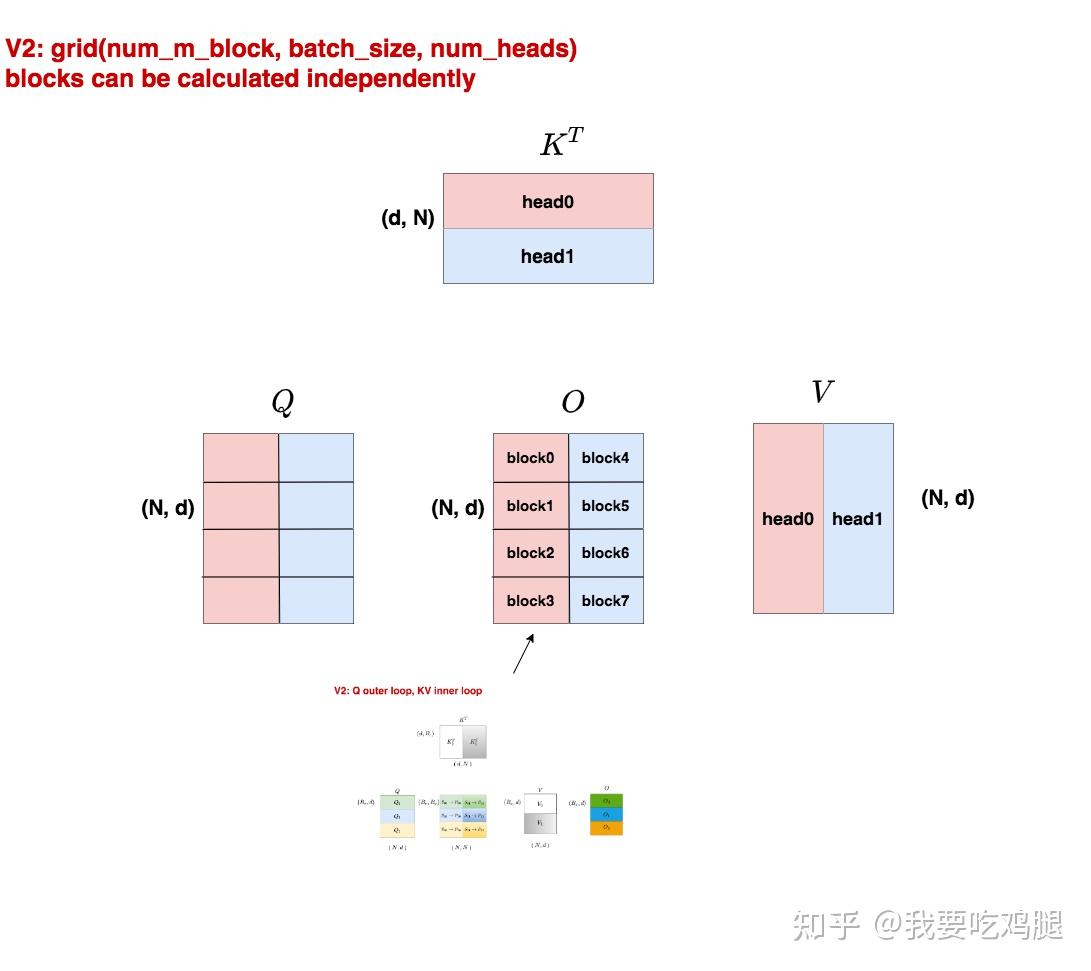
- 新的 Grid 划分: V2 启动的线程块网格(Grid)大小变为了
(num_m_block, batch_size, num_heads)。这里的num_m_block是一个新维度,代表将 Q 矩阵沿其序列长度方向切分成的块数。 - 解决并行度瓶颈: 通过引入
num_m_block,总的线程块数量变为了num_m_block * batch_size * num_heads。现在,即使batch_size和num_heads很小,我们依然可以通过增大num_m_block(即将长序列切成更多份)来创建出成百上千个线程块,从而确保 GPU 所有的 SM 都能被充分利用。
重排内外循环 (Loop Reordering)
为了让上述的序列维度并行能够最高效地执行,V2 对 V1 的核心循环结构做了一个至关重要的颠倒。

FlashAttention V2 算法伪代码
- V1 的循环: 外层循环遍历 K/V 块,内层循环遍历 Q 块。
- V2 的循环: 外层循环遍历 Q 块,内层循环遍历 K/V 块。
这个看似简单的顺序调换,带来了两大关键收益:
-
极大减少 HBM I/O:在 V1 的模式下,每处理一个新的 K/V 块(外层循环),都需要将所有 Q 块对应的中间输出 O_i 从 HBM 读入 SRAM,更新后再写回 HBM。而在 V2 的模式下,当处理一个 Q 块 Q_i 时(外层循环),其对应的中间输出 O_i 以及统计量 l_i, m_i 可以在整个内层循环(遍历所有 K/V 块)期间,一直驻留在高速的寄存器或 SRAM 中。它们只需要在内层循环全部结束后,被一次性地写回 HBM。这极大地减少了对 HBM 的反复读写,降低了 I/O 开销。
-
实现真正的块间并行:Attention 计算中,不同 Query(Q 的行)之间的计算是完全独立的。将 Q 的循环放在外层,完美地契合了这一特性。现在,每一个外层循环的迭代(处理一个 Q_i 块)都可以被分配给一个独立的线程块。这些处理不同 Q_i 块的线程块之间没有任何依赖关系,不需要任何通信,可以实现完美的并行计算。这正是 V2 能够高效利用
num_m_block并行维度的基础。
此外,将 Grid 维度组织为 (num_m_block, batch_size, num_heads) 还有一个额外的好处:可以提升 L2 Cache 的命中率。当处理同一个 batch 和 head 的不同 Q 块的线程块被连续调度时,它们都需要访问相同的 K/V 数据,后一个线程块有很大概率可以在 L2 Cache 中找到前一个线程块刚加载过的数据,从而避免了再次从 HBM 读取的延迟。
3.2.2 改进二:更优的 Warp 划分策略
在通过序列维度并行和循环重排优化了线程块之间(Inter-Block)的调度效率后,Flash Attention V2 进一步深入到线程块内部(Intra-Block),通过重新设计 Warp(线程束) 级别的工作模式,解决了 V1 中存在的通信开销问题。
一个线程块由多个 Warp 组成(在 Ampere 架构下通常是 4 个),这些 Warp 是 GPU 上实际并行执行的基本单位。如何将一个块内的计算任务(例如计算 Q_i K_j^T)分配给这些 Warp,直接影响了块内的计算效率。
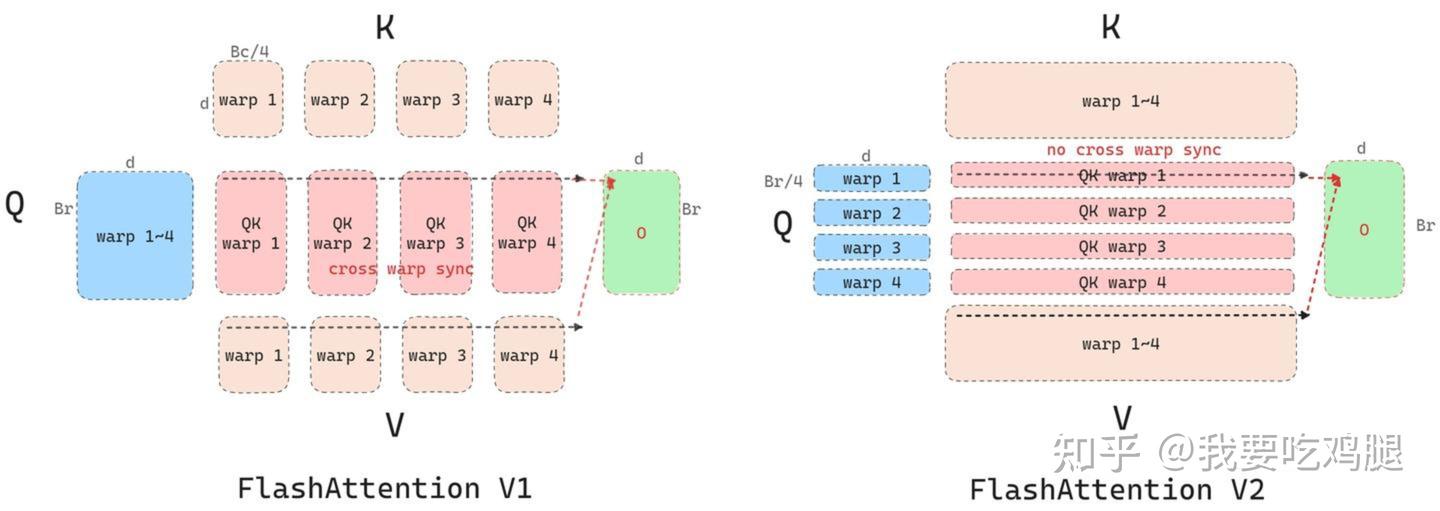
V1 的策略:Sliced-K 与跨 Warp 同步
如上图左侧所示,Flash Attention V1 采用了“Sliced-K”的划分方式:
任务分配: 块内的所有 Warp(warp 1-4)都从共享内存(SRAM)中读取相同的 Q 块。同时,它们各自负责处理 K 矩阵和 V 矩阵的不同切片(Slice)。
问题所在: 由于每个 Warp 只计算了基于部分 K/V 的局部结果,为了得到 Q 块中某一行对应的完整输出 O,必须将这 4 个 Warp 的计算结果进行一次规约(Reduction)操作,通常是求和。这个过程不可避免地需要跨 Warp 通信和同步(cross warp sync)。Warp 之间需要通过共享内存交换数据,并设置同步点(synchronization barrier)来等待彼此完成计算。
性能影响: 这种同步和通信会引入额外的延迟(latency)和开销,成为了块内计算的一个瓶颈。此外,从底层实现来看,这种划分模式在调用 cutlass GEMM 库时,会产生一种名为 "split-k" 的低效分布模式,进一步影响性能。
V2 的策略:Sliced-Q 与无通信并行
Flash Attention V2 巧妙地将任务划分方式颠倒过来,采用了“Sliced-Q”的策略:
任务分配: 块内的所有 Warp 现在都读取相同的 K 块和 V 块。与 V1 相反,它们现在各自负责处理 Q 矩阵的不同切片。
优势所在: 因为不同 Query(Q 的行)的计算是完全独立的,所以每个 Warp 现在可以独立地、完整地计算出其所负责的 Q 切片对应的输出 O,而无需与其他 Warp 进行任何交互。
性能影响: 如上图右侧所示,V2 的模式彻底消除了跨 Warp 的同步和通信需求(no cross warp sync)。每个 Warp 完成自己的计算后,可以直接将结果写回内存。这种“无通信”的设计减少了延迟,简化了逻辑,使得块内计算的效率大大提升。同时,这种划分也恰好避开了底层库的 "split-k" 低效模式。

所以 Flash Attention V2 仅仅通过对Q和KV的循环重排改进,就分别在两个不同的粒度上减少了同步和通信。
- 减少了线程块之间(Inter-Block)的通信:
- 这是通过“循环重排”和“序列维度并行”实现的。
- 在 V1 中,虽然不同
head和batch的线程块是独立的,但如果我们想在序列维度上并行(V1 后期版本也尝试引入了),就会变得很复杂,因为计算一个完整的 query 输出需要聚合所有 K/V 块的结果,这会导致处理不同 K/V 块的线程块之间需要通信。 - V2 将 Q 的循环放在外层,使得处理不同 Q 块的线程块之间变得完全独立。
block0负责计算Q_0的输出,block1负责计算Q_1的输出,它们之间没有任何依赖,因此完全不需要任何线程块间的同步或通信。
- 减少了块内 Warp 之间(Intra-Block)的通信:
- 这是通过“更优的 Warp 划分策略”(从 Sliced-K 到 Sliced-Q)实现的。
- 在 V1 的块内,所有 Warp 共同处理一个 Q 块,但各自处理 K/V 的不同部分。为了得到最终结果,它们必须通过共享内存进行一次跨 Warp 的同步规约(cross warp sync)。
- V2 让所有 Warp 共同处理一个 K/V 块,但各自处理 Q 的不同部分。由于不同 Query 的计算是独立的,每个 Warp 都能独立完成自己的任务,无需块内 Warp 间的同步。
总结一下:
V2 的循环重排优化是双重的:
- 宏观上,通过循环重排,消除了线程块之间在序列维度上进行并行计算时的通信需求。
- 微观上,通过改变 Warp 划分策略,消除了线程块内部 Warp 之间的同步需求。
通过这个看似简单的划分策略调整,V2 成功地将块内并行模式从需要协作和等待的“合作模式”,转变成了各自独立冲刺的“并行模式”,进一步压榨出了硬件的性能潜力。
3.2.3 改进三:减少非矩阵计算与 V2 策略总结
除了在并行策略上的宏观重构,Flash Attention V2 还在计算公式的细节上进行了打磨,旨在最大化利用 GPU 中效率最高的计算单元。
减少非矩阵(Non-Matmul)的冗余计算
- 背景: GPU 中有两种主要的计算单元:用于执行通用计算(如加法、指数、除法等)的 CUDA Cores,以及为矩阵乘法(Matmul)深度优化的 Tensor Cores。后者的计算吞吐量可以达到前者的数倍甚至十几倍(例如 16x)。因此,一个关键的优化方向是尽可能将计算转化为矩阵乘法,减少零碎的非矩阵计算。
- V2 的优化: Flash Attention V1 在每次内层循环更新输出 O_i 时,都需要进行一次完整的缩放(rescale)操作,这其中包含了多次逐元素的乘法和除法。V2 重新安排了计算流程,它在内层循环中累加的是未经完全归一化的中间值,直到内层循环(遍历完所有 K/V 块)的最后一刻,才进行一次最终的、合并的缩放操作,从而得到正确的输出块 O_i。
- 效果: 这种改变虽然看似微小,但它有效减少了在循环中反复执行的、低效的非矩阵计算量,相对地提升了 Tensor Cores 的计算占比,从而带来了性能增益。
V2 分块策略宏观总结
经过上述三个层面的深度优化,Flash Attention V2 形成了一套高度复杂且高效的并行计算策略。我们可以通过下面这张图来对其进行一个全局的、宏观的审视:
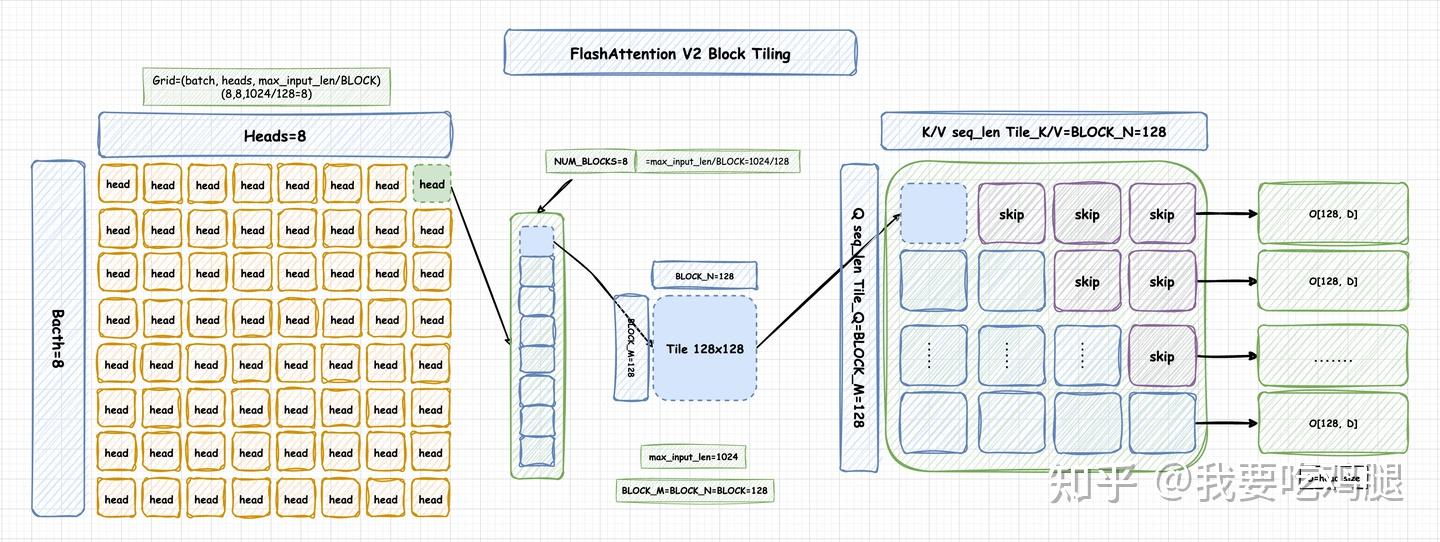
这张图为我们展示了当 batch_size=8, num_heads=8,序列长度为 1024 时,V2 是如何将一个庞大的 Attention 计算任务层层分解的:
1. Grid 层面: 任务被分解为 8 * 8 * 8 = 512 个独立的线程块(num_m_blocks * batch_size * num_heads)。
2. Head 层面: 图中从 64 个 head 中选取一个进行分析。
3. 序列并行层面: 这个 head 对应的长为 1024 的 Q 序列,被进一步切分为 8 个 num_m_block,每个块负责处理长度为 BLOCK_M=128 的一小段序列。
4. Tiling 层面: 每个线程块内部,为了计算其负责的那一小段序列(长度 128)的输出,会启动一个内层循环,遍历 K/V 矩阵的所有分块(BLOCK_N=128),进行 Tiling 计算。
5. 输出: 最终,每个线程块都独立地计算出最终输出矩阵 O 的一个大小为 128 x d 的子块,并写入指定位置。
这张图完美地总结了 V2 的核心思想:通过在多个维度(Batch, Head, Sequence)上进行极致的并行分解,创造出海量的、独立的、无需通信的计算任务(线程块),再让每个任务内部通过高效的 Warp 划分和优化的计算流来执行,从而将现代 GPU 的并行计算能力发挥到淋漓尽致。
四、Flash Decoding:为推理而生的专属加速
至此,我们已经深入探讨了 Flash Attention V1 和 V2 在模型训练过程中的革命性优化。然而,在模型的推理(Inference),特别是大语言模型的自回归生成(Autoregressive Generation)场景下,出现了一种全新的性能瓶颈,使得 V2 的优化策略不再适用。为了应对这一挑战,Flash Attention 的作者们专门开发了 FlashDecoding。
4.1 推理场景的特殊挑战
大语言模型的生成过程是逐个 token(词元)进行的。模型每生成一个 token,就会将其对应的 Key 和 Value 状态存入一个不断增长的 KV Cache 中。在生成下一个 token 时,模型会用当前这一个 token 作为 Query,去关注(Attend to)历史上所有 token 的 Key 和 Value。
这就构成了一个非常特殊的计算场景:
- Query (Q): 矩阵的序列长度维度始终为 1。
- Key (K) 和 Value (V): 矩阵的序列长度维度是历史上下文的总长度,可以变得非常长(例如,数万甚至数十万)。

FlashDecoding 推理场景示意图
上图直观地展示了这种极端不对称的情况:极短的 Query 对阵极长的 Keys 和 Values。
这个场景对 Flash Attention V2 造成了致命的打击。回顾 3.1 节,V2 的核心并行策略是在 Query 的序列长度维度上进行切分(num_m_block)来创建大量的并行任务。而现在,Query 的序列长度仅为 1,根本无法进行切分。
这意味着,对于单个 (batch_item, head),只能创建一个线程块来处理这个 Attention 计算。如果 batch_size 也很小,那么 GPU 的并行度将退化到 V1 早期的水平,甚至更差,导致大量的 SM 处于空闲状态,造成巨大的性能浪费。
因此,尽管 Flash Attention V2 在训练时表现卓越,但在长上下文的推理生成(long-context generation)这个关键应用场景下,其性能却远非最优。为了解决这个“Q 长度为 1”的特殊瓶颈,一种全新的并行策略——FlashDecoding应运而生。
4.2 Flash Decoding 的策略转变
面对“Q 长度为 1”这个无法并行切分的难题,FlashDecoding 的思路非常直接且优雅:既然无法在 Query 维度上并行,那就将并行的“屠刀”挥向唯一剩下的、并且足够长的维度——Key 和 Value。
核心思想:并行化处理 K/V Cache
FlashDecoding 的核心策略转变是,不再让单个线程块负责完整的 K/V 序列,而是将长长的 K/V Cache 切分成多个部分,然后启动多个线程块,让每个线程块只负责计算 Query 与其中一小部分 K/V 的局部 Attention 结果。
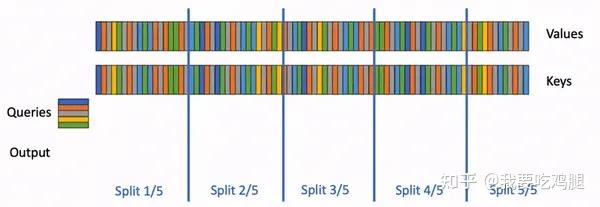
FlashDecoding 并行策略图解
上图清晰地展示了这一策略:
- 切分 K/V: 长长的 Keys 和 Values 序列被逻辑上切分成了 5 个部分(Splits)。
- 并行处理: GPU 可以同时启动 5 个线程块(或者更多,取决于切分粒度),
block0负责处理Split 1/5,block1负责处理Split 2/5,以此类推。 - 解锁并行度: 通过这种方式,并行度不再受限于恒为 1 的 Query 长度,而是取决于 K/V Cache 的长度以及我们切分的粒度。只要上下文够长,我们就可以创建出足够多的并行任务,从而再次让 GPU 的所有 SM 都高速运转起来。
这个策略的本质,是将 V2 中“一个线程块(处理一个Q块)遍历所有K/V块”的串行内循环,转变成了“多个线程块并行处理不同K/V块”的模式。通过这种“化串行为并行”的转变,FlashDecoding 成功地为推理场景解锁了大规模并行计算的能力。
4.3 实现方式
FlashDecoding 将策略转变为现实的实现方式,可以概括为一个清晰的两阶段流程:“并行计算局部结果” + “单个 Kernel 全局规约”。
第一阶段:并行计算局部结果
- 在这个阶段,FlashDecoding 将 K/V Cache 切分成多个块。
- 系统会启动多个线程块,每个线程块被分配一个 K/V 块。
- 每一个线程块内部,会独立地执行一个标准的 Flash Attention 计算(类似于 V1 或 V2 的内核),计算出它所负责的那一小部分 K/V 与当前 Query(长度为 1)的局部 Attention 结果。这个局部结果包含了局部的最大值 m_{local} 和局部的指数和 l_{local}。
第二阶段:单个 Kernel 全局规约 (Global Reduction)
- 当所有线程块都完成了局部计算后,它们会将各自的局部结果(m_{local}, l_{local} 等)写入 HBM。
- 此时,系统会启动一个额外的、非常轻量级的
reduceKernel。 - 这个
reduceKernel 的任务是:
- 从 HBM 中读取所有线程块产出的局部结果。
- 找到所有局部最大值 m_{local} 中的全局最大值 m_{global}。
- 使用全局最大值 m_{global} 对所有局部的指数和 l_{local} 进行正确的缩放(rescale),然后将它们相加,得到全局的归一化分母 l_{global}。
- 最后,用同样的方式对局部的输出进行缩放和聚合,得到最终完全正确的输出结果。
通过这种“分而治之”再“汇总统一”的方式,FlashDecoding 将一个原本因 Q 长度为 1 而无法并行的长序列计算,成功地分解成了可以在 GPU 上大规模并行执行的众多子任务。根据 Flash Attention 作者的报告,在处理 128K 的长上下文推理时,FlashDecoding 的速度可以比标准 Flash Attention 快 50 倍,极大地提升了大语言模型在长文本生成应用中的性能。
五、总结与展望
从标准 Attention 的 I/O 瓶颈,到 V1 的革命性诞生,再到 V2 的极致工程优化,最后到 FlashDecoding 为推理场景的专属加速,我们完整地追溯了 Flash Attention 家族的演进历程。
5.1 核心思想回顾
Flash Attention 的成功,本质上是一次算法与硬件协同设计的胜利。它最核心的洞察在于:在现代 GPU 架构下,制约性能的往往不是计算本身,而是数据在不同层级内存间的移动效率。通过 Tiling 和 Kernel Fusion,并辅以精妙的Online Softmax 数学技巧,Flash Attention 将一个内存限制(Memory-Bound)问题,成功转化为了一个计算限制(Compute-Bound)问题,从而在不牺牲任何精度的情况下,解锁了 Transformer 模型处理更长上下文的能力。
5.2 性能对比总结
为了帮助大家更清晰地回顾,我们将标准 Attention 与 Flash Attention 家族的各个变体进行总结对比:
| 特性 | 标准 Attention | Flash Attention V1 | Flash Attention V2 | Flash Decoding |
|---|---|---|---|---|
| 显存复杂度 | O(N^2) | O(N) | O(N) | O(N) (KV Cache) |
| I/O 复杂度 | O(Nd + N^2) | O(\frac{N^2 d^2}{M}) | O(\frac{N^2 d^2}{M}) (常数更优) | 针对性优化 |
| 核心并行策略 | Batch, Head | Batch, Head(现在也有Q序列) | Batch, Head, Q 序列 | Batch, Head, K/V 序列 |
| 主要适用场景 | 理论教学,短序列 | 模型训练 | 高性能模型训练 | 长上下文推理 |
5.3 价值与展望
Flash Attention 的出现,可以说是大模型发展史上的一个关键里程碑。它直接推动了模型上下文长度从数千(2k, 4k)级别到数十万(100k+)级别的跨越,使得处理整本书、长篇财报、甚至整个代码库成为可能,极大地拓展了 AI 的应用边界。
然而,技术的演进永不止步。随着硬件的不断迭代(例如 Hopper 和 Blackwell 架构的出现),以及对 Attention 机制更深层次的理解,优化的脚步仍在继续。Flash Attention V2 之后,更新的算法又是如何应对新的硬件特性?如何在支持滑动窗口注意力(Sliding Window Attention)和更复杂的 Attention 变体的同时保持极致性能?
这些问题的答案,都指向了 Flash Attention 家族的最新成员。敬请期待本系列的下一篇文章:《Flash Attention 全解析(下):Flash Attention v3 解析》。
参考文献
- 图解大模型计算加速系列:FlashAttention V1,从硬件到计算逻辑
- 图解大模型计算加速系列:Flash Attention V2,从原理到并行计算
- 原理篇: 从Online-Softmax到FlashAttention V1/V2/V3
- 原理&图解FlashDecoding/FlashDecoding++
内容效果不满意?点此反馈
