回答重点
长对话最怕的就是 context window 爆了(就像手机存储满了),要么请求直接报错,要么不得不丢消息导致模型”失忆”。
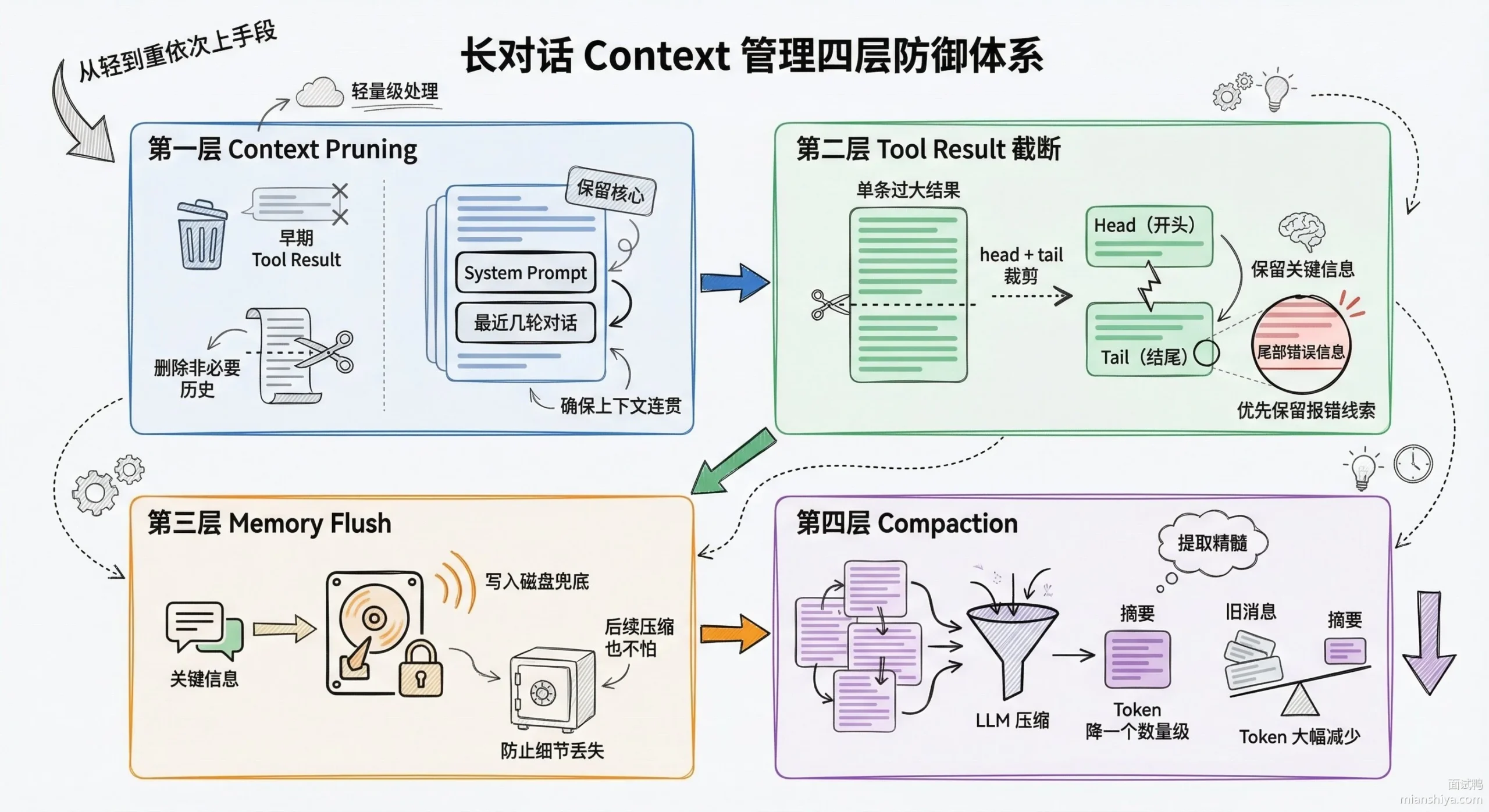
解决思路是 分层防御,从轻到重依次上手段,能小修就不大动。
第一层是 Context Pruning(上下文修剪),在每次向 LLM 发请求前清理不重要的内容。当上下文占比超过阈值时,对早期的 tool result 做 head+tail 裁剪甚至用 placeholder 替换。但最近几轮的 assistant 消息和 System Prompt 这些核心内容必须保留。
第二层是 Tool Result Context Guard(工具返回兜底),也运行在 transformContext 阶段。先对单条超出预算的 tool result 截断,如果所有 tool result 的总量还是超了,就从最早的开始用 placeholder 替换。这是一个实时安全网,保证送给 LLM 的 context 永远在安全范围内。
第三层是 Memory Flush(记忆刷盘),当 token 用量接近 compaction 阈值时,先让 Agent 把关键信息写到磁盘文件(memory/YYYY-MM-DD.md)做备份,防止后续压缩丢失重要细节。
第四层是 Compaction(压缩),用 LLM 把旧的对话历史压缩成摘要,替换掉原始消息。100 条消息压成一段摘要,token 消耗直接降一个数量级。因为在它之前已经做了 Memory Flush,关键信息已经落盘,摘要的有损压缩就可以接受了。
扩展知识
Context Pruning 的实现细节
OpenClaw 的 Context Pruning 实现在 src/agents/pi-extensions/context-pruning/ 目录,作为 pi-coding-agent 的 extension 注册在 context 事件上,每次向 LLM 发请求前触发。
它有两级阈值:softTrimRatio(默认 0.3)和 hardClearRatio(默认 0.5),分别触发裁剪和清除。
修剪策略有几个保护规则:
1)最近 N 条 assistant 消息不能删(默认 keepLastAssistants=3),模型需要它们来保持对话连贯性。
2)第一条 user message 之前的内容不能删,那里面是 System Prompt、SOUL.md 这些定义 Agent 行为的关键指令。
3)可以被修剪的是早期的 tool result(默认所有工具的返回都是 prunable 的,可通过 allow/deny glob 模式配置)。
- 当 context 占比 ≥ softTrimRatio 时,对过大的 tool result 做 head+tail 裁剪(保留前 1500 和后 1500 字符)
- 当 ≥ hardClearRatio 时,直接用 placeholder 替换。
另外还有一个 cache-ttl 模式(默认 TTL 5 分钟),两次修剪之间有冷却期,避免每次请求都重复扫描。
Tool Result 截断的巧妙设计
src/agents/pi-embedded-runner/tool-result-truncation.ts 里有个很聪明的处理:截断时通过 hasImportantTail() 检测尾部是否包含 error/diagnostic 内容(匹配 error、exception、exit code、traceback 等关键词)。
如果有,会采用 head+tail 策略优先保留尾部。
因为错误信息通常比正常输出更有价值,一个命令跑了 200 行正常日志最后一行报了 OOM,你砍掉尾部留开头,模型以为执行成功了,这就出大问题了。
Tool Result Context Guard 兜底机制
installToolResultContextGuard() 在 src/agents/pi-embedded-runner/tool-result-context-guard.ts 中实现,通过包装 Agent 的 transformContext 方法拦截。
它会计算一个 context budget(context window × 4 chars/token × 0.75 headroom)。
然后,先对超出单条上限的 tool result 截断。
如果总量还是超了,就从最早的 tool result 开始用 "[compacted: tool output removed to free context]" 替换。
不管前面的修剪和压缩有没有到位,这一层兜底保证送给 LLM 的 context 永远在安全范围内。
Compaction 摘要的质量问题
用 LLM 做摘要看起来很优雅,但实际上有个隐患:摘要质量不可控。LLM 可能会遗漏关键细节,比如用户之前提到的一个配置参数、一个特定的文件路径。
如果后续对话恰好需要这些信息,模型就会凭空编造或者表示不知道。
所以 OpenClaw 在 compaction 之前先做 Memory Flush,让 Agent 把关键信息写到 memory/YYYY-MM-DD.md 文件里。
Compaction 本身还有 identifier preservation 指令,要求摘要保留 UUID、hash、URL、文件名等不可重建的标识符。
类似的思路在 ChatGPT 的 Memory 功能里也能看到,它会在对话中提取关键事实存到持久化的 memory store,跨会话都能用。
面试官追问
提问:Compaction 压缩摘要的时机怎么选?太频繁或太晚都有问题吧?
回答:太频繁会浪费 token 和增加延迟,每次压缩本身就是一次 LLM 调用,128K 的上下文压缩一次可能就要花几千 token。太晚又会导致 context 逼近上限,留给新消息的空间不够。OpenClaw 用的是 pi-coding-agent 库内置的自动 compaction 机制,当上下文 token 逼近模型窗口时自动触发。在 compaction 之前,Context Pruning 已经在低阈值(默认 30% 开始裁剪 tool result,50% 开始用 placeholder 替换)做了第一道减负,这样 compaction 不需要太频繁触发。同时 Memory Flush 也有独立的触发条件(softThresholdTokens 默认 4000),确保在 compaction 前关键信息已经落盘。
提问:压缩后的摘要本身也会越来越长,怎么处理?
回答:如果对话足够长,摘要确实会不断累积。处理方式是摘要本身也可以被再次压缩,做滚动摘要。比如第一次压缩 1-50 条消息生成摘要 A,第二次把摘要 A 和 51-100 条消息一起压缩成摘要 B。每次压缩都是把旧摘要和新消息合并后重新总结,保证摘要长度相对稳定。代价是越往后,早期信息的保真度越低,但对于绝大多数场景来说,50 轮前的细节已经不重要了。
提问:Context Pruning 删掉的 tool result,如果后面模型又需要了怎么办?
回答:有两种恢复途径。第一,如果是文件内容类的 tool result(比如 read_file),文件本身还在磁盘上,模型可以再次调用工具读取。第二,Memory Flush 机制会在 compaction 之前让 Agent 自行判断哪些关键信息需要持久化,写到 memory/YYYY-MM-DD.md 文件中。注意 Memory Flush 不是按工具类型选择性保存 tool result 原文,而是让 LLM 自行提取和总结关键信息落盘。比如重要的决策、配置参数、任务进度等。所以它保存的是”语义级别”的关键信息,不是 tool result 的原始副本。
