循环神经网络: 是处理文本、股票、语音等序列数据的核心模型。
1. CNN的尴尬:看不懂顺序
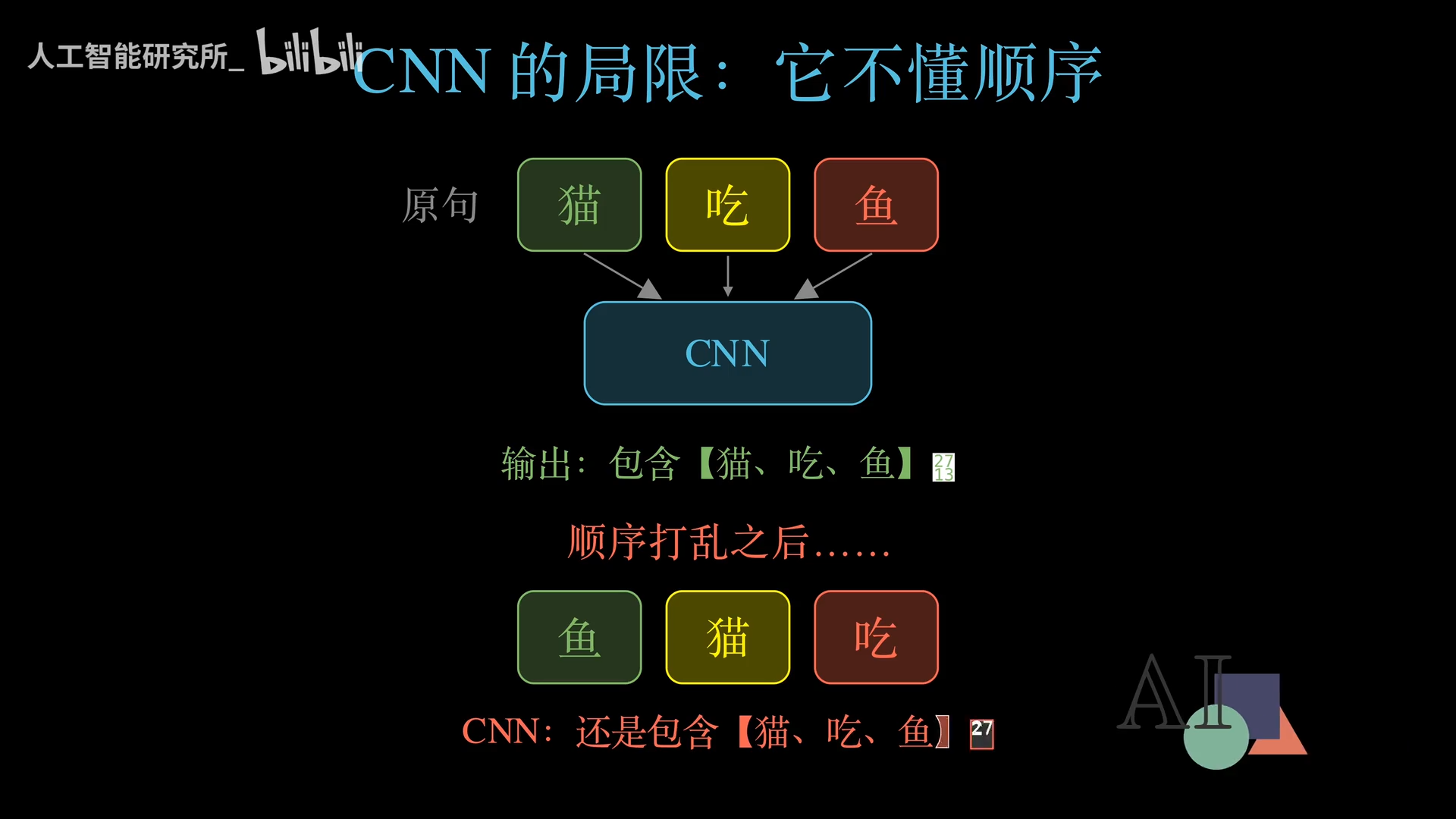

如果你给CNN一张猫吃鱼的图片,它知道有猫、鱼、吃。但如果你把文字换成“鱼猫吃”,CNN同样认为这三个词同时出现了,看不出语病。更极端的是“狗咬人”和“人咬狗”,CNN无法区分意思的差异。
原因很简单:CNN擅长提取空间特征(比如图像的边缘、纹理),但对序列顺序不敏感。而现实世界中,语序决定语义,时间决定趋势。
2. 什么是序列数据?
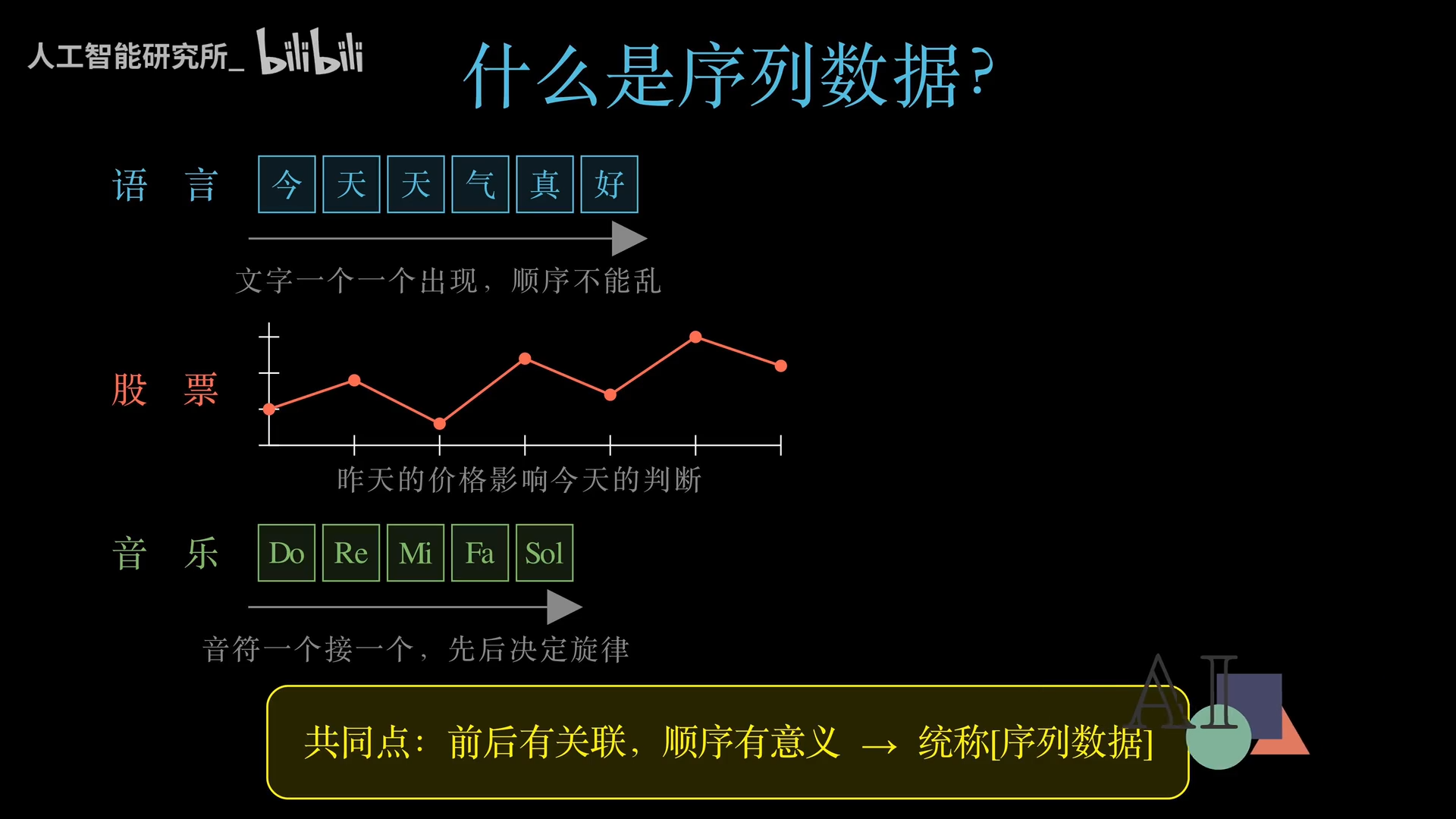
序列数据的特点是:前后有关联,顺序有意义。例如:
- 文字:“我”后面可能是“爱”;
- 股价:今天受昨天、前天甚至上月的影响;
- 语音、视频帧:连续帧之间存在依赖。
3. 人类怎么处理序列?
大脑有一个“缓存”机制——每读一个新词,会结合前面所有的上下文,形成一个动态的“实时记忆”。所以你读到“床前明”时,大概率能猜到下一个字是“月”。这就是人类理解序列的秘密:当前信息 + 历史记忆 = 理解结果。
4. RNN的核心思想
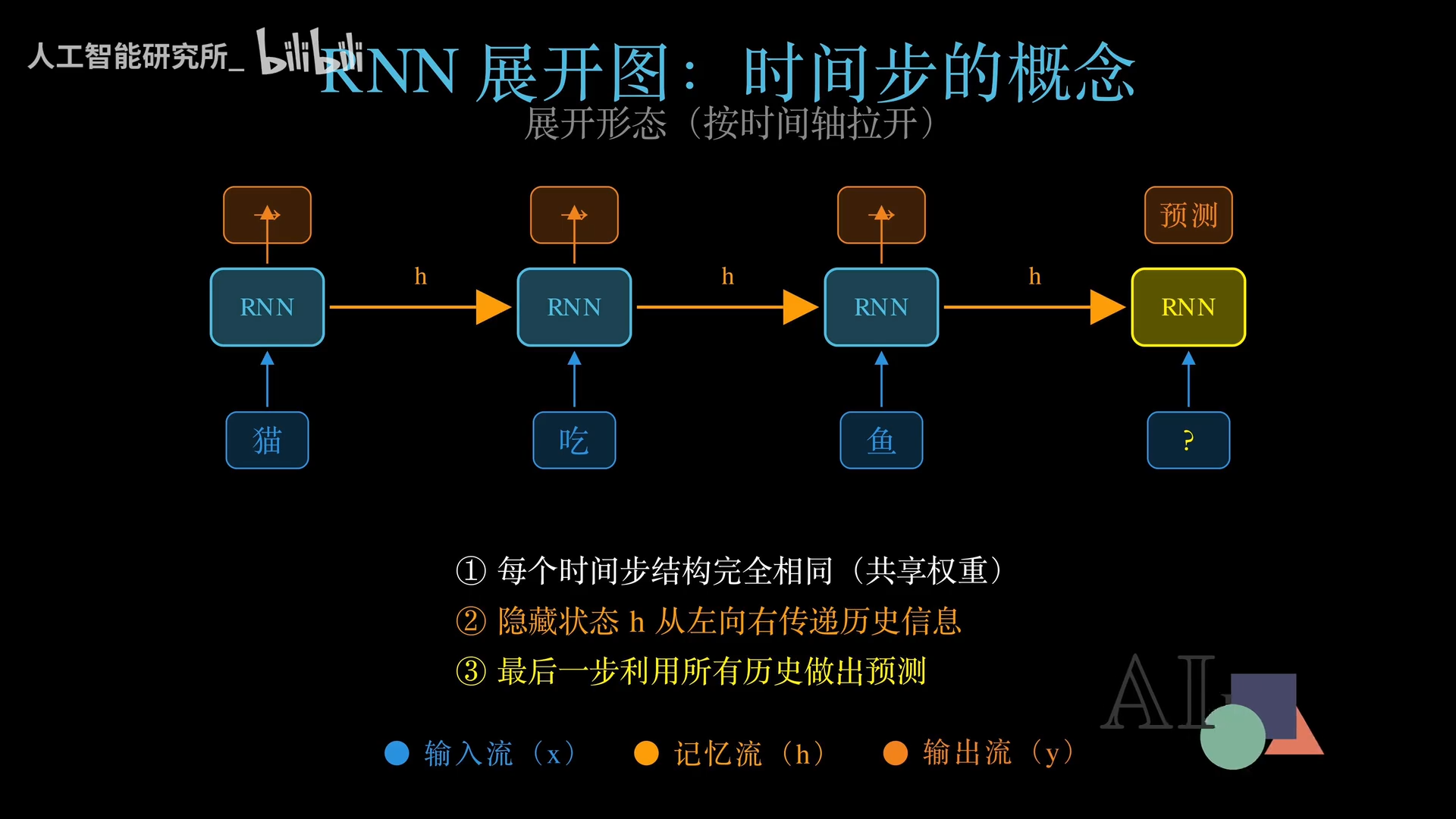
RNN模仿了这个机制。普通神经网络的神经元一次性处理所有输入,没有记忆;而RNN在每一步都维护一个隐藏状态(Hidden State),相当于一个小本本。每一步处理当前输入时,会翻开小本本,看看历史信息,然后将新旧信息融合后,再写入小本本。
- 参数共享:图中看似有多个时间步的方块,其实是同一个网络在不同时刻的复制,权重完全共享,极大节省计算资源。
5. 实战:RNN如何猜下一个词?
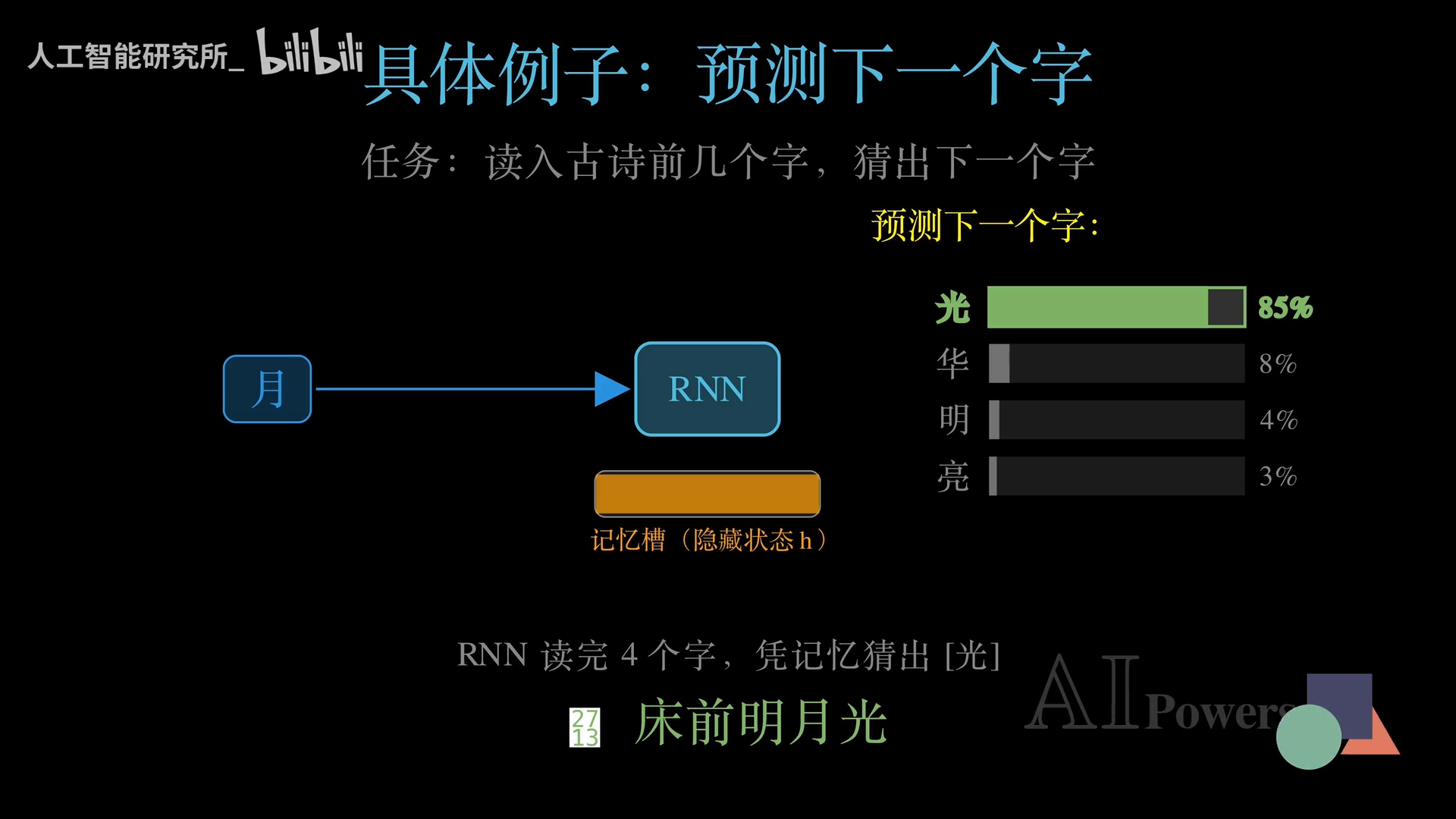
输入“床”,RNN的记忆槽记录25%的印象;接着“前、明、月”依次进入,每输入一个字,记忆都更新一次。读到“床前明月”后,RNN大概率猜到下一个字是“光”。整个过程只允许一次读一个字,靠记忆积累完成预测。
6. RNN的现实应用

- 机器翻译:理解整句逻辑后才能翻译;
- 语音识别:捕捉随时间变化的声波;
- 文本生成:根据开头续写故事;
- 股价预测、输入法补全等。
7. RNN的短板与改进方向

- 优点:具备短期记忆,能处理变长序列。
- 缺点:随着序列增长,最早期的信息在层层传递中会被不断稀释(梯度消失/爆炸)。你无法指望RNN读完一本小说后还记得第一章的内容。
为了解决这个“健忘症”,下一代的LSTM(长短期记忆网络)和GRU(门控循环单元)被设计出来,通过门控机制有选择地记忆和遗忘信息。
思考题与答案
1. CNN和RNN在数据处理上的本质区别是什么?
CNN擅长捕捉空间特征(如图像),但不擅长建模顺序;RNN通过隐藏状态传递历史信息,专门用于处理序列数据。
2. RNN的隐藏状态有什么作用?
隐藏状态充当“记忆载体”,在每一步将历史信息传递给下一步,使得网络在处理当前输入时能利用过去的上下文。
3. RNN参数共享有什么优点?
显著减少参数量,使模型能处理任意长度的序列,并提升泛化能力(参数共享是循环结构的核心之一)。
4. 为什么RNN在长序列上表现不佳?如何改进?
因为梯度消失/爆炸问题:长序列反向传播时,梯度连乘导致早期信息被稀释。改进方法包括使用LSTM(引入遗忘门和输入门)或GRU(简化结构)。
