
注意: kv cache 只针对有 mask 机制的 decoder only 的模型
KV Cache 用空间换时间,把固定不变的 K、V 存下来;而 Q 每步一换,旧 Q 不再被查询,所以没必要缓存。
每个输入 prompt,在计算第一个 token 输出的时候,每个 token 的 attention 肯定是都要从头计算。但是在后续 token 的生成中,都需要计算 self-attention,也就是输入 prompt 以及前面输出的 token 的 attention。这是就需要用到前面每一个 token 的 K 和 V,由于每一层的参数矩阵是不变的,此时只有刚生成的那个 token 的 K 和 V 需要从头计算,输入 prompt 和之前生成的 token 的 K 和 V 其实是跟上一轮一样的。
我们可以把每一层的 K、V 矩阵缓存起来,这就是所谓的 KV Cache。
🌠为什么没有 Q cache?
计算注意力矩阵 QxKT 时,每次只有一个 q 进行计算,所以并没有 Q cache.也就去说,当新输入 xn,注意力的计算(见注意力矩阵最下面一行)与 q 1,q 2,...qn-1 无关,因此无需缓存 Q 矩阵
在注意力计算中,新 token 的 Q 需要与所有历史 token 的 K 做点积,即:
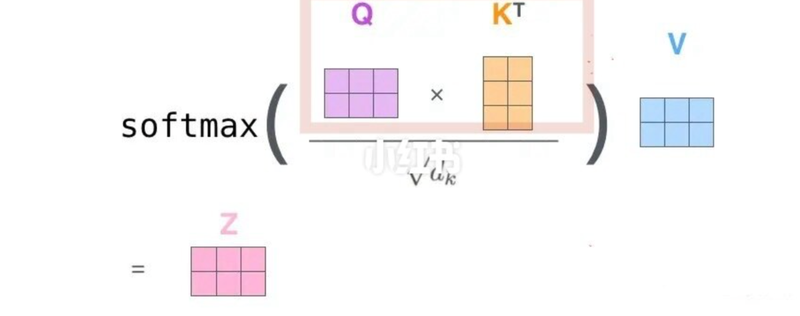
为了计算这个点积,我们必须拥有所有历史 K 的完整矩阵(包括它们的转置形式)。
如果每步都不缓存 K,那就得重新计算每个历史 token 的 K(包括重复的前向传播),这会导致计算量按序列长度二次增长。
所以,“因为需要 K 的转置”其实道出了缓存 K 的必要性——K 的转置本身不改变值,但它需要全部历史 K 的值。
而 V 也是同理,因为加权求和时需要所有历史 V。
不过更准确地说:
- K 被缓存,是因为每个新 Q 需要查询所有历史 K,计算新的 token 与之前词的注意力分数。因此必须缓存 k 矩阵
- V 被缓存,是因为每个新 Q 需要从所有历史 V 中加权求和,也必须缓存 v 矩阵。
- 这个查询过程恰好需要用到 K 的转置(其实就是用转置来表达新词与之前的老词之间的关系度),但转置只是访问形式,不是缓存的根本原因。
Comments NOTHING