
[[transform代码]]
在Transformer里,通过引入token间的注意力,让每个token都有机会根据上下文不断地更新自身的向量嵌入。接下来就详细介绍自注意力机制。每个token在初始向量嵌入的基础上,通过共享的3个线性层进行映射,分别得到3个向量,即query向量、key向量、value向量,简称为q、k、v向量。(1)q向量是查询向量,对其他token的k向量进行查询。(2)k向量是应答向量,对其他token的q向量进行应答。(3)v向量是值向量,用来更新其他token的向量嵌入。
Transformer里用的是点积。如果q4和k3的相似度最高,则用v3来更新“苹果”这个token的向量嵌入时权重就最大
之所以叫作自注意机制,是因为这里的注意力的计算是对token所在序列自身所有token进行的。
公式里为什么会除以根号 dk呢?其中dk是token特征的维度,Transformer里是512维。这是因为原始的q向量和k向量默认均值为0,方差为1,经过点乘后,是dk个q和k中的值乘积相加,那么得到的结果均值还为0,但是方差变为dk。为了让点积后的结果仍然保持方差为1,就要除以标准差,也就是
类似于在卷积神经网络里,可以定义多个卷积核,在自注意机制里,同样可以定义多个q、k、v并分别进行各自的注意力机制计算。每个q、k、v被称为一个头。每个头可以关注不同的语义特征,
在实际的多头注意力机制的实现时,并不是每个token生成多个q、k、v向量,而是q、k、v向量都只生成一个和原始token特征维数一样的向量,然后将q、k、v向量拆分成多份。每份代表一个头。同样,在多头注意力机制下,也可以用Q、K、V矩阵来进行加速度计算。Q、K、V矩阵也被划分为多个头,最终对多个头计算的结果进行拼接。
架构简单的介绍
Transformer模型架构的编码器部分前文已经讲解了。首先输入是原始的自然语言的句子。经过字典转换为token,然后将token对应到可学习的向量嵌入。向量嵌入接下来传入多头注意力模块,多头注意力模块的输入和输出有一个残差连接。接下来是前馈模块,同样对前馈模块输入和输出进行残差连接。多头自注意力模块、前馈层和各自的层归一化、残差连接合起来便构成了一个编码器。这样的编码器在Transformer的原始实现里有6个。因为编码器的输入和输出的维度是一样的,所以可以简单地累加起来,以此增加模型的深度,让模型学习到更抽象的概念
用户在问为什么在前馈神经网络(Feed-Forward Network / FFN)中,要先放大特征维度再缩小回来。这是一个很好的问题,涉及到 Transformer 中 FFN(也叫 MLP)的设计原理。
这个问题通常出现在 Transformer 架构中,比如:
输入: 512 维
↓ 放大 (Linear 1)
中间: 2048 维 (通常放大 4 倍)
↓ 激活函数 (ReLU/GELU)
↓ Dropout
↓ 缩小 (Linear 2)
输出: 512 维
python
class FeedForward(nn.Module):
def init(self, embed_dim, expansion_factor=4):
super().init()
self.fc1 = nn.Linear(embed_dim, embed_dim * expansion_factor) # 放大
self.dropout = nn.Dropout(0.1)
self.fc2 = nn.Linear(embed_dim * expansion_factor, embed_dim) # 缩小
def forward(self, x):
return self.fc2(self.dropout(F.gelu(self.fc1(x))))
为什么要这样做?
-
增加模型容量和非线性表达能力:
- 放大后,隐藏层的维度变大了,可以学习更复杂的特征表示
- 虽然最后会缩小回来,但在这个高维空间中,特征可以被"展开"和"重组",学到更复杂的模式
-
参数量和计算量的权衡:
- 如果只是单一线性层(embed_dim -> embed_dim),表达能力有限
- 如果两个都是放大(embed_dim -> 更大),计算量太大
- 先放大后缩小是一个很好的平衡,可以用相对较少的参数获得更强的表示能力
-
类比人的理解:
- 低维空间:有限的组合方式
- 高维空间:更多的组合可能性,可以表示更复杂的函数
位置编码
需要找一个编码函数,它需要是周期变化的,低维度的数字变化得快,越高维度的数字变化越慢。这就像数字进位一样,在计数过程中,个位变化最快,接下来是十位、百位等,越高维的数字变化越慢,模型通过学习,可以掌握这种周期变化的规律,从而在推理时可以处理训练时没有见过的序列长度。可以考虑sin()函数,它是周期变化的,而且是连续的,通过设置输入的系数,可以改变sin()函数的波长,如图2-14所示。sin()函数输入系数越小,波长越长。用波长短的sin()函数生成位置编码的低维度,用波长长的sin()函数生成位置编码的高维度。
位置编码的维度和原始特征编码的维度是一致的,它们都是512维。每个维度的位置编码的值都是用这个token在序列里的位置和这个编码的位置作为sin()函数的输入生成的,维度越高,sin()函数的波长越长,函数值随位置变化越慢,
同样sin()和cos()函数都是随着维度增加波长增加的,那么加入cos()函数的好处是什么呢?注意力机制是通过q向量和k向量的点积来计算的。对于用sin()和cos()交替进行编码的两个位置向量,一个位置是t,另一个位置是t加Δt。对这两个位置编码进行点积运算如下:
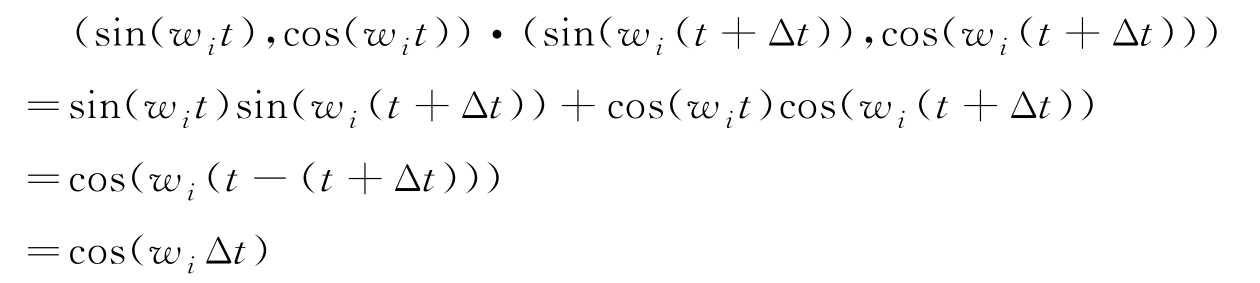
通过上边计算可以看到最后注意力计算结果只与两个位置之间的相对位置Δt有关,而和绝对位置t无关。这对于自然语言处理是非常重要的,因为一个词组的意思只和这个词组里单个字之间的相对位置有关,而和这个词出现在句子里的绝对位置无关。
Comments NOTHING