AI 总结
为何LLM大语言模型“偏爱”旋转位置编码?
你发现了吗?传统的位置编码在如今LLM大语言模型下显得黯然失色,取而代之的是旋转位置编码。位置编码如何“旋转”?其设计又有哪些精妙之处?今天我们就来彻底拆解这个看似玄妙却无比优雅的技术。
一、传统位置编码的“贴便签”式困境
在Transformer架构中,由于模型是并行处理序列,天生没有语序感,因此我们必须手动注入位置信息。传统的绝对位置编码(如正余弦编码)采取一个极其直觉的动作:贴便签。
系统为每个词生成一串代表位置的向量,就像一张张“位置便签”,直接相加到词向量上。在短句子里(比如十几个词),这个操作毫无问题:便签上的数字不大,词向量原本的语义地貌没有被破坏。
但大模型的野心远不止读句子——他们要读整篇文章、整本书。当文章长度膨胀到4000个词,便签上的数值开始偏大,就像在一张精美的水彩画上用越来越粗的马克笔写字,画面的底色被掩盖,模型对词义的感知开始出现偏移。当来到32000个词,便签的数值已经变成庞然大物,直接淹没了精妙的语义信号。
核心问题:加法会改变数值分布。 序列一长,位置便签反客为主,把语义这个“底图”毁了。传统方案在短文本是解药,在长文本却变成了毒药。
二、旋转位置编码(RoPE):让指针自己“转”起来
有没有一种位置编码方式,既能告诉模型词的位置,又绝对不破坏词向量的数值分布?答案是肯定的,它的核心操作不是相加,而是旋转。这就是RoPE(Rotary Position Embedding)。
想象一下:每个词的embedding向量不再是躺在坐标系里不动的死数据,而是一根指南针的指针。
- 位置0:AI的指针指向一点钟方向(默认角度)
- 位置1:改变(Change)的指针顺时针转了一个角度
- 位置2:世界(World)的指针又转了一个角度,总共转了两个角度
也就是说,第N个词的向量 = 原始向量旋转了N个角度。位置信息没有被写进坐标,而是被编码成了指针转过的角度。
这种设计的巧妙之处在于:相对距离变成了几何上的夹角。AI和改变之间隔了一个位置,指针夹角刚好是一个固定角度;AI和世界之间隔了两个位置,指针夹角刚好是两个固定角度。位置差 = 角度差——不管这两个词在句子开头还是结尾,只要相隔距离一样,它们指针之间的夹角就永远一样。相对位置信息被锁在了几何结构里。
三、为什么Attention能“天然”感知相对距离?
自注意力机制的核心是计算Q(查询)和K(键)的内积(点乘)。在RoPE下,模型先让Q的指针转一个角度,再让K的指针转一个角度,然后做点乘。根据三角函数的几何性质,两个长度不变的向量旋转后做点乘,结果只取决于它们之间的夹角!
这意味着:Q和K的内积天然只看相对距离,完全不受绝对位置影响。这简直是“梦中情码”。
四、从直觉到数学:二维旋转矩阵
我们先把直觉翻译成严谨的公式。假设一个词在未注入位置信息时的二维embedding向量为(x1, x2)。要旋转一个角度θ,使用旋转矩阵:
[cosθ -sinθ] [x1]
[sinθ cosθ] [x2]
其中θ = m·c(m为绝对位置编号,c为预设常数,控制旋转步进速度)。当m=1时转到某个位置,m=20继续往前转……关键几何现象:无论向量怎么转,端点始终落在同一个圆上。向量的**模长(能量)**完全没有改变,只是绕着原点画圈。坐标变了,但骨子里的语义能量被原封不动保留下来。
这正是RoPE完胜传统加法的根本原因:传统加法像用力拉扯箭头,模长随位置漂移;RoPE旋转让箭头原地跳芭蕾,长度始终如一,改变的仅仅是指向的角度(位置信息)。
五、复数视角下的“魔法化简”
对于更高维度,我们需要更锋利的工具——复数。在复数平面里,任何二维向量都可看作一个复数。旋转动作变得极其简单:直接乘以旋转因子 e^(iθ)。
- 查询向量Q在位置m = 原始Q × e^(imc)
- 键向量K在位置n = 原始K × e^(inc)
旋转后的Q和K做内积(Attention得分),在复数中通过取共轭后相乘并取实部得到。化简时指数部分合并,代表绝对位置的m和n融为一体,变成了m – n!无论两个词在文章的第100位还是第1000位,只要距离m-n相同,Attention得分就完全相同。
这就是RoPE最核心的数学奇迹:Attention的得分在数学底层被强制绑定在了相对距离上。 模型根本不需要学习如何计算相对位置,因为旋转的几何性质已经帮它做死了。
六、高维实现:两两配对与“分块对角矩阵”
真实的embedding向量动辄512维甚至4096维,如何扩展?答案藏在两两配对的策略中:
- 想象有512个人要跳舞,不能让他们手拉手在同一个大广场上转圈(会乱成一团)。正确做法是:1号和2号组成一队,在属于自己的小圆毯上旋转;3号和4号另一队,互不干扰。以此类推。
翻译成矩阵就是分块对角矩阵——左上角2×2小方阵负责旋转x1、x2,右下角负责旋转x3、x4……其他区域全是零。这些零不是废料,而是隔离墙,死死锁住维度边界,防止交叉污染。
当维度扩展到512维时,RoPE的真实形态是一个巨大的分块对角矩阵,里面有256个互不干扰的2×2旋转小方块。位置信息像细密的螺纹一样,成对拧进了embedding的每一个角落。
七、工程优化:99.6%的存储节省
如果真去存这个512×512的矩阵(26万多个元素,只有1024个有用,占比不到0.4%),计算资源将极度浪费。实际工程中采用极其聪明的捷径:
- 只存两个长度为512的向量:cos函数向量(按顺序存储每对维度对应的余弦值)、sin函数向量(存储正弦值)。
- 总元素数:512+512=1024个,相比26万个大矩阵,节省99.6%存储。
用这两个向量完成旋转只需三步:
- 原始向量与cos函数逐位相乘
- 把原始向量的元素做“翻转”操作(rotate half),再与sin函数逐位相乘
- 两步结果相加,完成旋转
没有矩阵乘法,没有循环嵌套,只有三次最基础的逐元素运算。计算速度提升约256倍,内存节省99.6%——这就是RoPE工程实现的精髓。
八、Rotate Half:压缩密码
Rotate Half到底是什么?以四维向量(x1, x2, x3, x4)为例,执行该操作后:
- 第一对(x1, x2):x2取反后和x1交换位置 → (-x2, x1)
- 第二对(x3, x4):→ (-x4, x3)
这个取反+交换恰好等价于那个巨大的旋转矩阵里非零元素对向量所做的事。它用一个元素翻转完美模拟了整个矩阵乘法的效果,GPU最擅长干这种活,跑起来飞快。
九、多速度设计:显微镜+望远镜
你可能好奇:为什么不让所有维度以同样速度旋转,统一管理不好吗?答案:这会导致灾难。
- 如果全部转极快(全秒针):转几十圈后指针回到几乎一样位置,模型分不清距离10和1010的词。
- 如果全部转极慢(全时针):相邻词之间指针角度差几乎为零,模型连谁前谁后都分不清。
RoPE的精妙在于多速度设计:不同维度组的旋转速度不同,由频率常数θ决定。θ越大转得越快,θ越小转得越慢。一个简洁的指数递减公式控制着256对维度的频率:
频率 = 1 / (10000^(2i/d))
- i:维度对索引(0,1,2…)
- d:总维度数
- 公式逻辑:i越大,指数越负,频率越小 → 维度索引越大,旋转越慢。
画成曲线:起点频率很高(1.0),随后急速下坠。低维度(秒针)疯狂旋转,负责分辨相邻词序(显微镜);高维度(时针)几乎静止,捕捉跨篇章的宏观结构(望远镜)。1万倍的速度落差,从极速到几乎静止,全部压缩在256对维度之内。
十、外推性:低频维度是“安全绳”
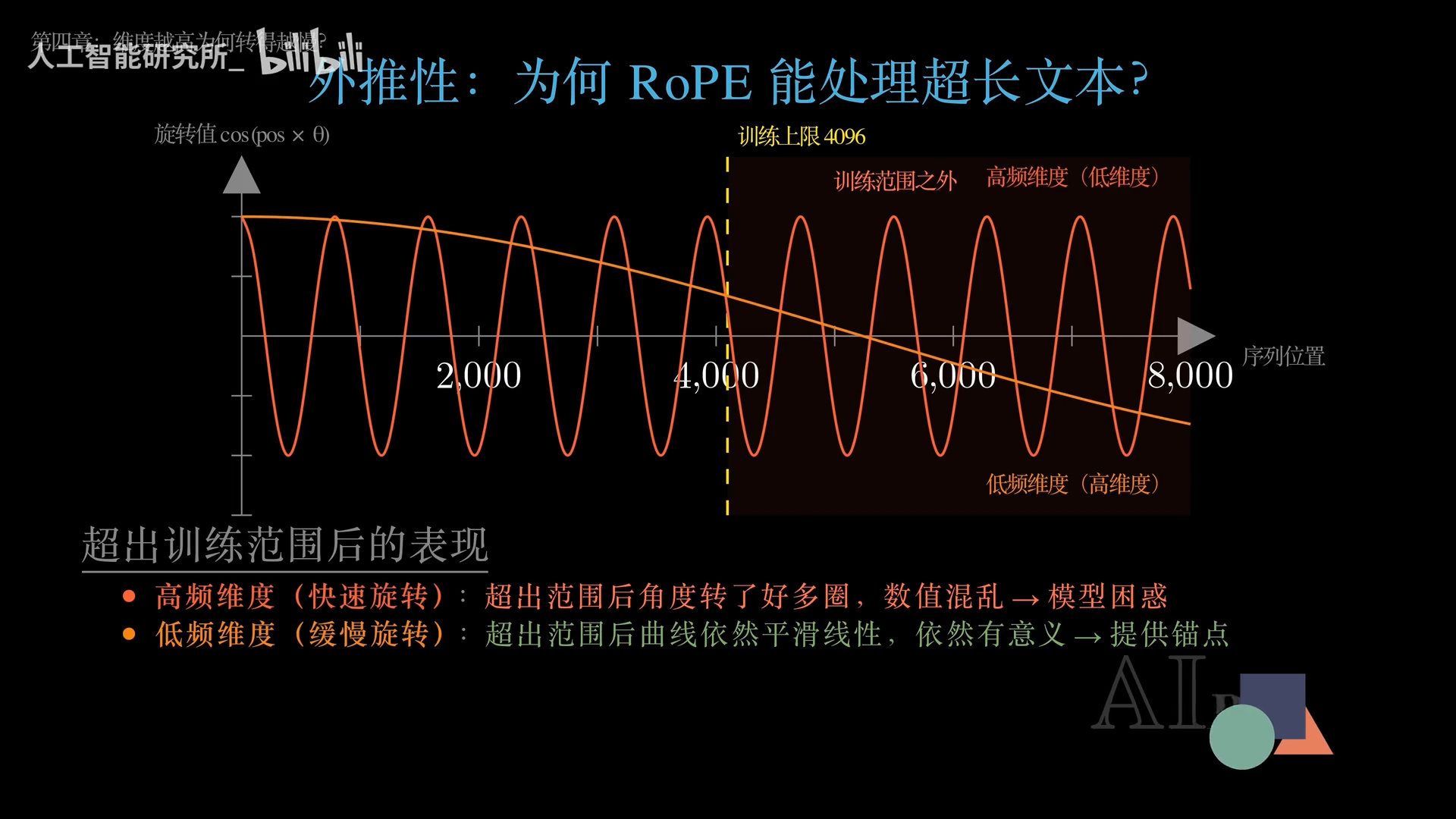
(这个“低频维度”指的是 旋转速度较慢的维度对。
在 RoPE 的多速度设计中,每个 2 维分块的旋转速度由公式控制:
频率 = 1 / (10000^(2i/d))
- i 较小的维度(如 i=0,1):频率高 → 旋转速度快 → 被称为高频维度(秒针)
- i 较大的维度(如 i=127,128):频率低 → 旋转速度慢 → 被称为低频维度(时针))
大模型面临最头疼的问题之一:训练时最长文本4096词,推理时突然给一篇8192词的长文——模型会崩溃吗?
对于传统绝对位置编码,这叫越界,模型直接崩溃。但RoPE展现出惊人韧性。
原因在于低频维度(时针)。当位置编号超出训练范围(如4096),高频维度(秒针)因为转了太多圈,数值混乱变成噪声;但低频维度曲线依然平滑、线性、可预测。它就像抛向深渊的一根安全绳,死死拽住模型,不让它在长文本中迷失方向。
基于此,当前大模型圈最火的技巧RoPE Scaling应运而生:人为调慢所有维度的旋转速度(频率缩放),让原本在4096就会崩溃的高频维度,到8000甚至32000都还在安全区内平滑变化。这就是为何像LLaMA、GPT等模型仅凭一个频率缩放参数,就能将上下文窗口从4K扩展到32K甚至128K的根本原因。
总结对比
| 项目 | 传统绝对位置编码 | RoPE旋转位置编码 |
|---|---|---|
| 操作方式 | 加法(贴便签) | 旋转(保持模长) |
| 对模长影响 | 改变模长,长序列淹没语义 | 模长不变,能量守恒 |
| 相对位置感知 | 需要学习或隐式 | 几何结构天然保证 |
| 长文本外推 | 极差,越界崩溃 | 强,低频维度提供锚点 |
| 工程效率 | 简单但效率低 | 高,99.6%存储节省 |
思考题
1. 为什么传统绝对位置编码在长文本中会导致模型“失忆”?
答案: 传统方案使用加法注入位置信息。当序列变长,位置便签的数值不断增大,加到词向量上后会改变原本的语义数值分布,甚至完全淹没语义信号。模型看到的是被扭曲的数字,自然无法分辨前后文含义。
2. RoPE是如何实现“保持模长不变的旋转”的?其数学本质是什么?
答案: RoPE利用旋转矩阵(或复数乘法)对词向量进行旋转。旋转操作不改变向量的模长(长度),只改变其方向(角度)。数学本质是:向量在旋转过程中始终落在同一个圆/球面上,能量守恒。这使得位置信息被编码为角度,而不损害语义特征。
3. 为什么RoPE能天然支持长文本外推(out-of-distribution)?
答案: 因为RoPE中存在多速度设计:高频维度(快速旋转)在超出训练长度后数值混乱,但低频维度(慢速旋转)依然保持平滑、线性、可预测的特性。这些低频维度相当于“安全绳”,为模型提供宏观的位置指引,使得即使位置编号超出训练范围,模型仍能理解相对关系。通过进一步调整频率缩放,可以平滑扩展到更长的上下文。
