主流向量数据库介绍
一、为什么需要向量数据库?
随着大语言模型(LLM)和RAG(检索增强生成)技术的流行,传统数据库无法高效处理非结构化数据的语义检索。向量数据库专门用于存储和检索高维向量(Embedding),能够实现快速相似度搜索,是构建智能问答、多模态检索、推荐系统等应用的核心组件。
二、主流向量数据库对比
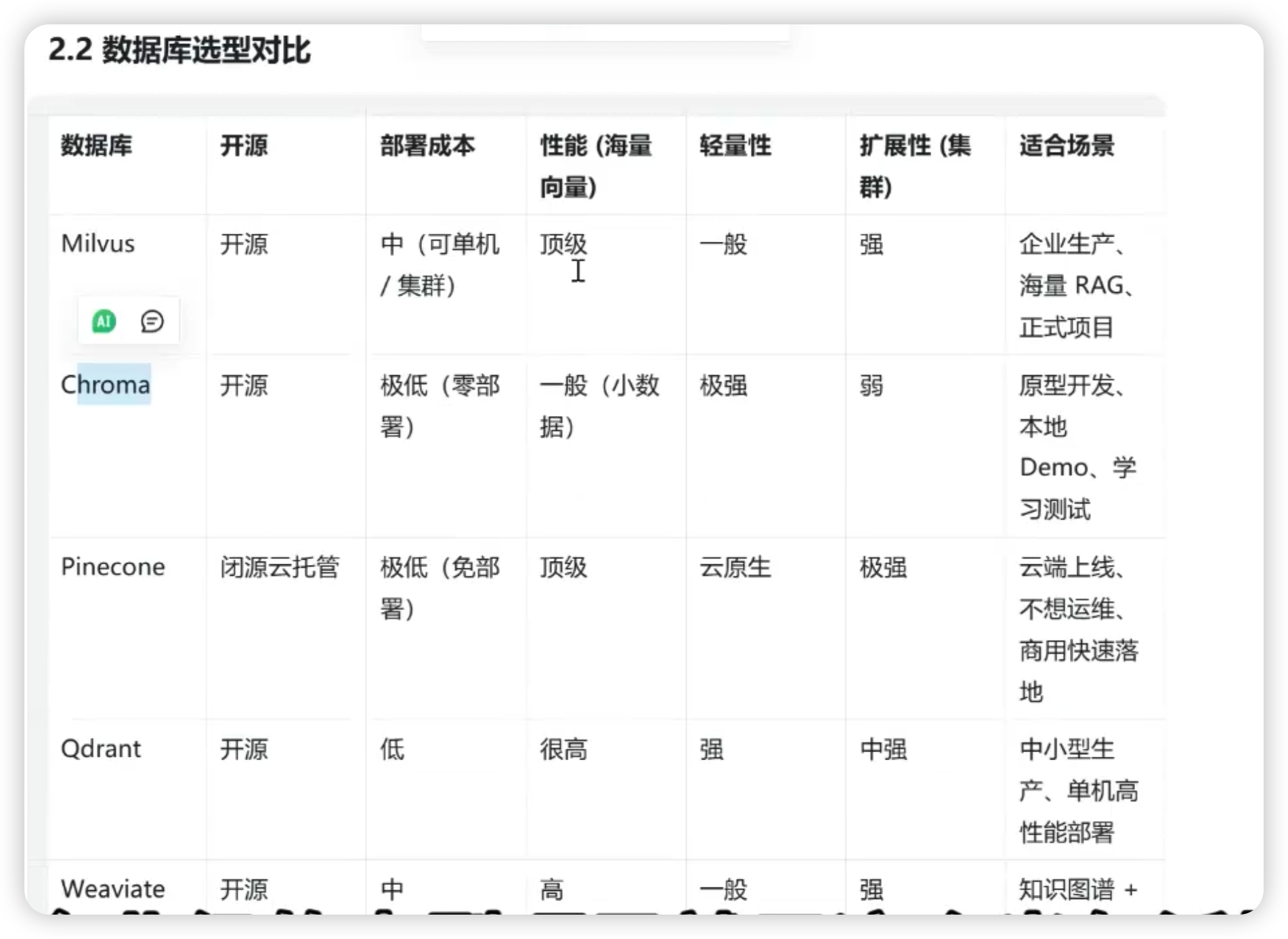
1. Milvus(米尔沃斯)
定位:企业级开源分布式向量数据库,工业级首选。
核心优势:
- API友好,支持Python、Java、Go等多种编程语言
- 适配LangChain和LlamaIndex全生态(两个主流的RAG框架)
- 性能强悍:10亿级向量可实现秒级检索
- 支持分布式集群、水平扩容(通过增加服务器来扩展存储和计算能力)
- 支持多种索引类型
缺点:
- 本地单机部署较重,对机器配置要求较高
适用场景:
- 企业级生产环境
- 海量向量数据
- 正式RAG项目
2. Chroma
定位:轻量级开源向量数据库,个人学习和小型项目首选。
核心优势:
- 一行代码即可安装(pip install chromadb),无需额外部署
- 数据存储在本地,开箱即用
- 与LangChain无缝集成,零配置即可做RAG
- 自带Embedding、文档切分、向量存储一体化
缺点:
- 不适合大规模数据,仅适用于个人学习或小型Demo
适用场景:
- 个人学习向量数据库
- 快速原型开发、Demo演示
- 小样本RAG实验
import chromadb
from sentence_transformers import SentenceTransformer
# 加载预训练的模型,这里使用的是 MiniLM-L6-v2 模型
embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
# ✨ 推荐:使用 PersistentClient 创建持久化客户端
client = chromadb.PersistentClient(path="./vector_db")
collection= client.get_or_create_collection(name="konwledge_base", metadata={"hnsw:space": "cosine"})
docs = [
"Obsidian关闭插件更新通知:设置-第三方插件,取消自动检查插件更新",
"向量数据库Milvus适合千亿级分布式向量检索,支持多模态",
"Qdrant使用Rust开发,单机性能强,部署简单",
"PGVector是PostgreSQL向量扩展,复用SQL事务能力",
"Chroma轻量本地向量库,适合个人本地RAG原型开发"
]
# 给每条文档唯一ID
doc_ids = ["doc1", "doc2", "doc3", "doc4", "doc5"]
# 5. 生成文档向量并存入数据库
exist_count = collection.count()
if exist_count == 0:
print(f"集合已存在 {exist_count} 条数据,继续添加新数据...")
doc_vectors = embedding_model.encode(docs).tolist()
collection.add(
embeddings=doc_vectors,
documents=docs,
ids=doc_ids
)
print("知识库向量入库完成!\n")
else:
print(f"集合已存在 {exist_count} 条数据,无需添加新数据。")
user_query = "本地Obsidian怎么关闭插件更新弹窗"
# 生成查询向量
query_vector = embedding_model.encode(user_query).tolist()
results = collection.query(
query_embeddings=[query_vector],
n_results=2
)
print(f"用户查询问题:{user_query}")
print(f"查询结果:{results}")
# results = {
# # 外层列表:每个查询一条结果
# # ↓ 因为只传了 1 个查询,所以外层列表长度 = 1
# 'ids': [ ['doc1', 'doc2'] ], # 第 1 个查询的 2 个结果
# 'documents': [ ['文档1全文', '文档2全文'] ], # 第 1 个查询的 2 个结果
# 'distances': [ [0.234, 0.567] ], # 第 1 个查询的 2 个相似度
# 'metadatas': [ [None, None] ],
# }
for idx,text in enumerate(results['documents'][0]):
distance = results['distances'][0][idx]
print(f"相似度距离:{distance:.4f} | 内容:{text}")
定位:云原生托管向量数据库,无需自己部署服务器。
核心特点:
- 完全云端服务,通过API调用
- 适合不想自行部署基础设施的团队
- 收费服务
适用场景:
- 快速上线云端RAG项目
- 企业不想自己运维数据库
4. Qdrant
定位:高性能轻量开源向量数据库,介于Chroma和Milvus之间。
核心优势:
- 用Rust编写,性能高、内存占用低
- 单机性能可吊打很多竞品
- 支持持久化、向量过滤、丰富的检索条件
- 既可单机也可集群
适用场景:
- 中小型项目
- 需要轻量但又能抗一定生产负载的场景
5. Weaviate
定位:向量+知识图谱混合型数据库。
核心特点:
- 同时支持存储向量和实体关系
- 语义检索+知识图谱一体化
- 支持自研Embedding(也可使用开源Embedding模型)
- 支持多模态数据关联查询
缺点:
- 学习难度较大,上手比Milvus和Chroma复杂
- 需要一定的知识图谱背景
适用场景:
- 复杂语义推理
- 行业知识图谱增强的RAG
6. Redis(向量插件)
定位:原本是缓存数据库,通过插件支持向量检索。
优势:
- 无需新增数据库组件,运维成本低
缺点:
- 向量检索性能不如专业向量数据库
- 大数据场景下性能一般
建议:专业的事情交给专业的工具做,Redis本身是为缓存设计的,虽然可以兼职做向量检索,但不建议在生产环境中用于大规模向量查询。
三、选型建议
| 适用场景 | 推荐数据库 |
|---|---|
| 个人学习、实验 | Chroma |
| 中小型项目 | Qdrant |
| 企业级大型项目 | Milvus |
| 不想自己部署 | Pinecone |
| 需要知识图谱能力 | Weaviate |
四、思考题
1. 为什么个人学习推荐使用Chroma而非Milvus?
答案:Chroma只需pip安装即可使用,无需部署服务器,零配置就能做RAG实验;而Milvus需要较复杂的分布式部署,对机器配置要求高,适合生产环境而非学习环境。
2. 什么是“水平扩容”?为什么重要?
答案:水平扩容是指当数据量增大时,通过增加更多服务器节点来分担存储和计算压力,而不是单纯提升单台服务器的配置。它对于处理海量向量数据(如10亿级)至关重要,因为单机无法承载无限增长的数据量。
3. 为什么不建议用Redis来做向量数据库?
答案:Redis本质上是缓存数据库,其向量检索是附加功能,性能不如专业的向量数据库(如Milvus、Qdrant)。在需要高效语义检索的生产环境中,应选择专门优化过的向量数据库,以保证检索速度和准确性。
