字幕




原模型是 6×8 乘八乘的四层结构
而 LER 的参数矩阵都是 62 与 28
8×2 与 2×8
8×2 与二成这样的形状
所以总体上可以把 LAURA 模型表示成由 62 乘 882 乘八
8×2 乘三个网络拼起来的七层网络
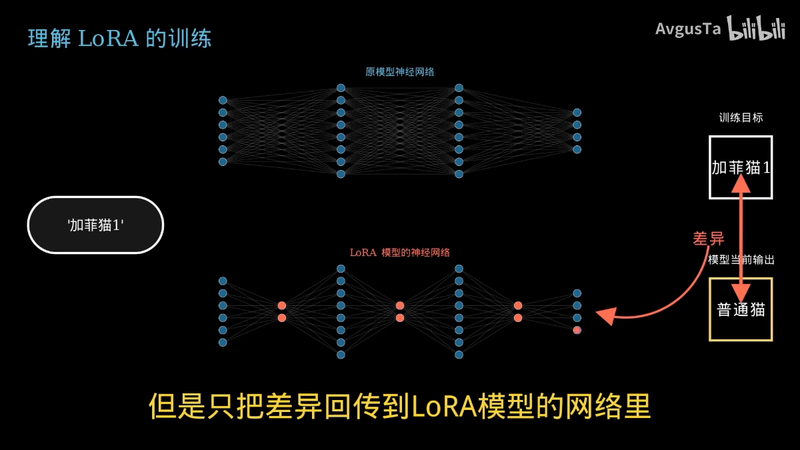
我们还是训练让模型学习加菲猫的知识信息
把加菲猫一词和加菲猫图片分别放在两个网络两端
将加菲猫一词同时输入两个网络
然后得到输出结果
因为最开始 LAURA 模型所包含的知识信息和原模型是相同的模型
还是只输出一个普通猫
所以我们仍然是度量普通猫和我们想要的加菲猫的差异
但是只把差异回传到 LAURA 模型的网络里
这样要计算的就只有 LAURA 模型中的参数了
计算量大大减少
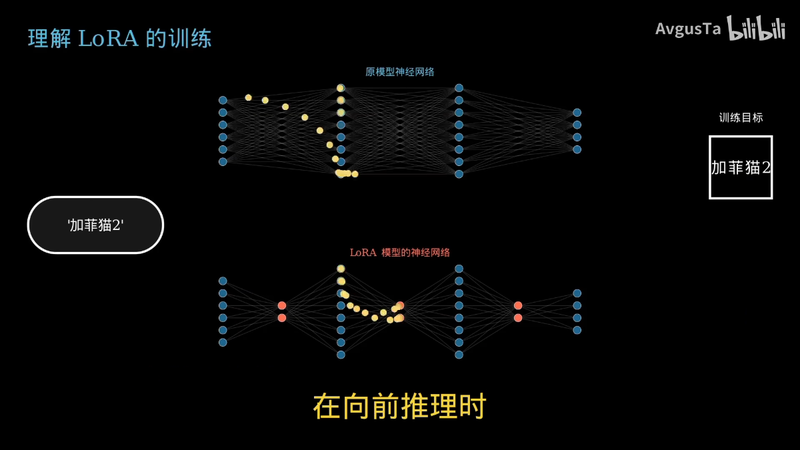
再向前推理时
让信息同时流经原网络和 LAURA 网络
输出的结果为原网络的输出和 LAURA 网络的输出相加的和
而在向后回传时
只把差异回传给 LAURA 网络
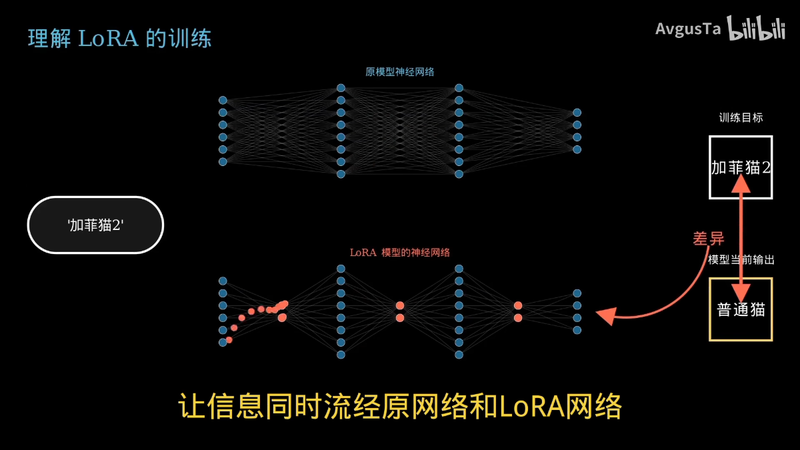
这样重复训练
不断更新 LAURA 网络的参数
LAURA作为同时拥有低训练算力需求加超小体积加即插即用优点的存在
是解决给模型增加新信息知识任务的
毫无疑问的版本答案
本系列将以可视化数学演示来带大家无门槛直观的理解
这些AIJC基础设施背后的逻辑
那么在理解LAURA模型原理前
我们应该先回答如何让模型获得之前未获得的信息知识的问题
在上期可视化DEFUSION模型的视频里
我们提到过神经网络的训练
就是同时把要输入的内容和要得到的内容放在神经网络两端
让输入的内容流经网络来得到神经网络的预测对比
神经网络预测结果和我们想要得到的内容
然后把差别回传到网络中
让网络各个节点根据预测结果和我们想要的结果的差异
来修正自己的参数
使得在下一次预测的结果更贴近我们想要的结果
以此为基础
我们能很自然而然的想到一个简单粗暴的办法
那就是把新的信息知识也放在神经网络两端
继续在已经训练好的神经网络的基础上
再接着训练几文
比如想让模型能根据加菲猫这个词生成加菲猫的图像
我们就可以把加菲猫一词和加菲猫的图像分别放在网络两端
让模型不停的回传自己的输出结果
与加菲猫图像的差异来调整自己的参数
用各种加菲猫图片不停重复几轮后
模型就能顺利根据加菲猫一词生成加菲猫图片了
当然这样也带来一个很大的问题
那就是网络中所有的参数都要重新训练
对于现实中动辄上亿参数的网络来说
这么做训练成本可能会很大
那么如何解决呢
在LAURA出现之前的常见做法是只训练网络中的某几层
比如我们把网络的前三层之间的参数冻结
只训练第三四层之间的参数
这样每次回传差异时
就只需要对第三四层之间的参数进行计算调整
计算量大幅的减少了
对于问模型增加某些特定信息知识的任务来说
并不是所有的参数都是有必要训练的
通过只训练其中的一部分
我们也能得到非常理想的效果
但是这样仍然有一个问题
那就是每次为了让模型获得新信息知识
我们要训练
然后保存整个模型
这样实在是太笨重了
那么有没有一种方法既能大量减少模型训练的计算量
又能用很小的文件体积来保留这些新信息知识呢
有的那就是LAURA
在理解LAURA之前
我们要先看一下一个数学小花招
我们这里有两个以行和列形式来表示的数字表格
当然你也可以叫它们矩阵
当我们要把这两个矩阵相乘时
就是把左边矩阵的第一行的各个数字
分别乘以右边矩阵第一列的各个数字
然后加起来
这样就生成了结果矩阵第一行第一列的数字
这样依次类推
用左矩阵的第一行与右矩阵第二列就能得到结果
矩阵第一行第二列的数字
用左矩阵的第二行与右矩阵第一列就能得到结果
矩阵第二行第一列的数字最后就能生成整个结果
矩阵当我们左矩阵只有一行
右矩阵只有一列式生成的结果
矩阵就只有一个数字
而当左矩阵只有一列
但有很多行
右矩阵只有一行
但有很多列式
我们却得到一个比较庞大的结果
矩阵理解了这些
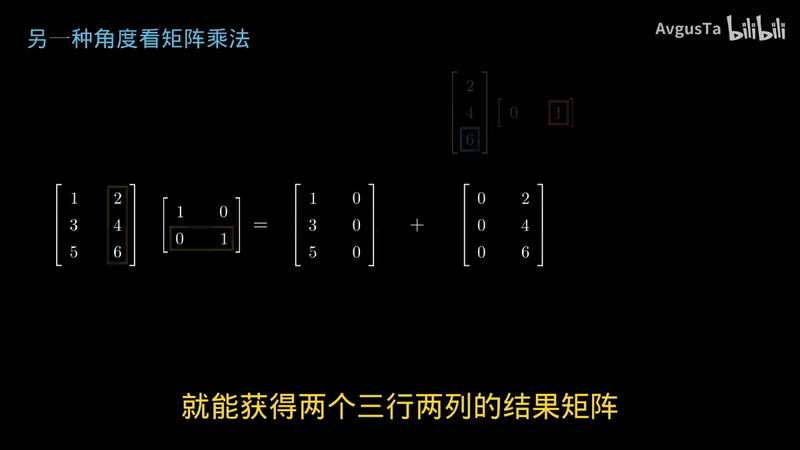
我们可以从另一个视角来看矩阵的乘法
我们可以假装左边的矩阵是两个独立的三行一列的矩阵
而右边矩阵是两个独立的一行两列矩阵
这样我们分别对左右两个矩阵的两个组成部分来进行乘法
就能获得两个三行两列的结果矩阵
然后把两个矩阵叠起来
让各个对应位置数字相加
获得的最终矩阵和我们直接进行乘法的矩阵完全一样
这样我们就能理解一种经典的矩阵重构技巧
我们把结果矩阵放在左边
把它拆成两个矩阵
以及一串从大到小排列的权重的乘积
分别用左边矩阵的各列与右边矩阵的各行乘出和结果矩阵一样
尺寸的矩阵
把矩阵的各个数字乘以权重
然后不断地叠起来
就能用这些得到的矩阵还原重构出原本的结果
矩阵
这种小花招在数学上被叫做奇异值分解
是线性代数的灵魂
当然在刚才的动画中
你可能注意到了
当我们把权重为五的矩阵和权重为二的矩阵叠在一起后
所得到的结果就已经非常接近完本的结果矩阵了
也就是说
通过这种方法
我们可以把矩阵拆分成很多同尺寸矩阵的组合
这些同尺寸的矩阵本身所携带的信息的重要程度不同
而对应的权重数字就反映了它们的重要程度
当我们把前两个最重要的矩阵叠加后
就已经反映了原矩阵的大部分信息
我们也可以用灰度图像来更直观地理解这种拆分与重构
众所周知
灰度图像其实就是一个矩阵
各个像素代表矩阵对应位置的数字
数字大小代表该像素发白的程度
我们可以通过刚才的拆分与重构方法
来获得一个对于灰度图像的近似图像
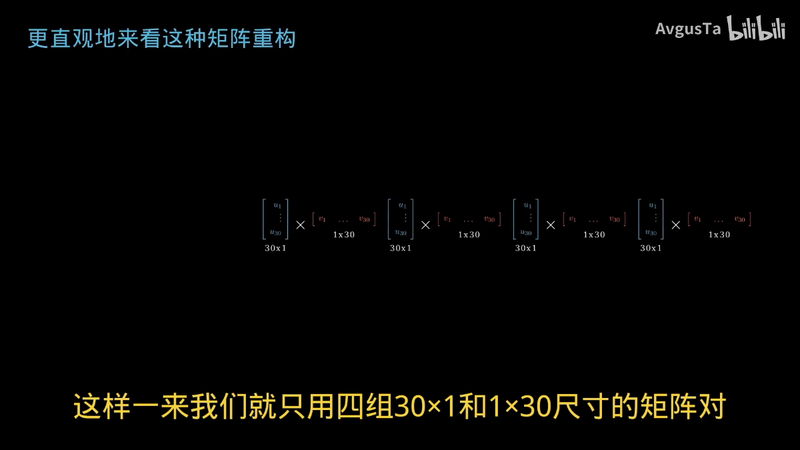
把原先30×30尺寸灰度图像的矩阵拆分成30个
30×30尺寸的矩阵
然后只挑其中重要程度最高的四个叠起来
这样一来
我们就只用四组30×1和1×30尺寸的矩阵对
也可以表示为一组30×4和4×30尺寸的矩阵对
重构出了原本30×30尺寸的灰度图像
矩阵的近似
只用了240个数字
就表示出了原本900个数字的绝大部分内容
了解了这套数学小技巧
我们就能很容易地理解LAURA的原理
我们知道神经网络由一堆节点和不同层节点之间的连接构成
而这些节点之间的连接就是神经网络的核心
每一条连接代表一个参数
数字连接的数量越多
神经网络模型的体积就越大
对于一个4×6乘以6×4的四层神经网络
各层之间节点的连接所代表的参数就可以用三个矩阵来代表
比如第三层
第四层分别有六个和四个节点
总共就是有6×4=24个连接
我们可以很自然地把这24个数字放在一个6×4的矩阵中
那么接下来我们要做什么就很明显了
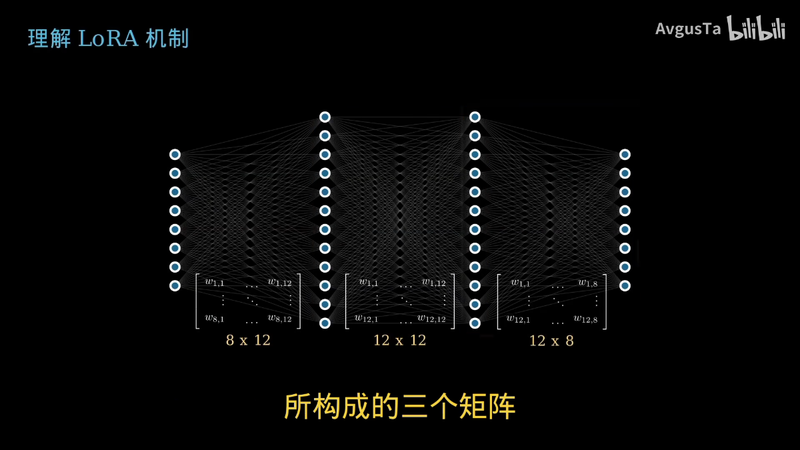
比如对于一个8×12乘
12×8的矩阵的全部连接参数所构成的三个矩阵
我们可以重新使用之前矩阵拆分重构的技巧
只挑这些矩阵拆分结果中最重要的两个叠起来
就能把它们拆成这样8×2与2×10
二
12×2
2×10
二
十
2×2与2×8这三对矩阵对
这样一来
原本336个数字才能表示的神经网络
被我们用128个数字就高度近似地表示出来了
这就是LAURA的核心原理
通过对神经网络的参数矩阵的拆分与重构
只用很少的数字数量很小
文件体积就能抽取出原本神经网络模型的绝大部分信息
知道了LAURA的核心原理
我们就能很直观地理解LAURA的训练和参与推理的过程
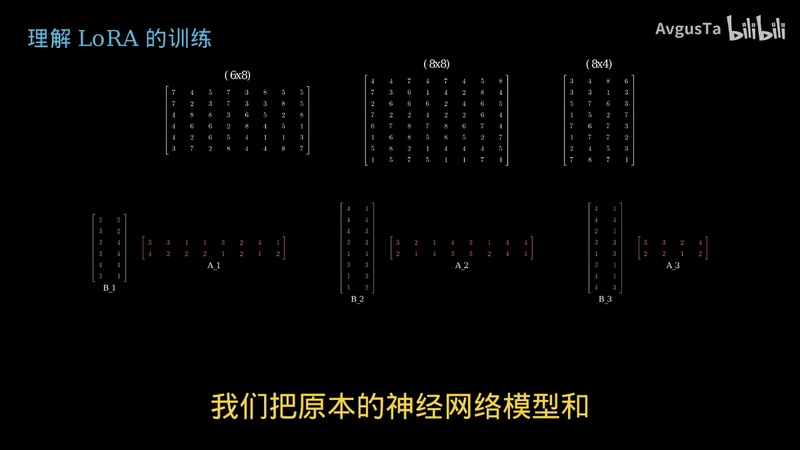
我们把原本的神经网络模型和layer模型的参数矩阵
重新表示为节点和连线
就能得到我们想要的加菲猫输出
通过这样的结构
原网络仍然是不停地输出普通猫
而LAURA则负责输出加菲猫和普通猫的差值
两者输出加起来就是加菲猫了

而LAURA参与推理的过程就更加简单了
我们把LAURA的62与28
8×2与2×8
8×2与2×3个矩阵对相乘
恢复成和原模型的参数矩阵相同的尺寸

然后把两个矩阵叠加起来
让相同位置的数字相加
这样原本的神经网络模型在叠加了LAURA后
就获得了LAURA中所保存的信息知识
原模型的普通猫的知识和LAURA的加菲猫与普通猫的差值的知识
加在一起
就是加菲猫的知识模型就能顺利地输出加菲猫的图像
了解了这些
我们就能轻松地理解LAURA的一些关键参数
最重要的一个就是LARA的权重了
我们还是把LARA的矩阵对相乘恢复成和原模型的参数矩阵相同的尺寸
但是我们给每个矩阵中的所有数字乘以我们指定的参数

像画面中这样全部乘以0.5后
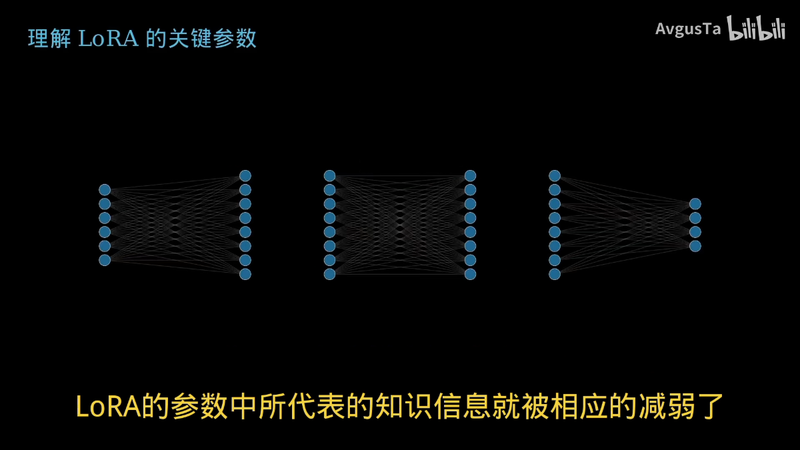
LARA的参数中所代表的知识信息就被相应的减弱了
再与原模型的参数矩阵叠加起来
重新推理
得到的就是不那么加菲猫的加菲猫了
虽然大多数时候使用LAURA就是直接使用一个整体权重
但我们也是可以对每个lower矩阵对设置不同的权重大小的
比如像这样给lower矩阵分别设置0.8
0.6和0.2的权重
就能分别控制LARA的知识信息对神经网络不同层的影响
同时LAURA也解决了一个非常大的痛点
使用LAURA我们可以轻松的同时给原模型附加多个LAURA的知识信息
比如我们同时使用加菲猫和米老鼠的LAURA
其实就是把加菲猫和米老鼠lower的参数矩阵都叠到原模型参数矩阵上
这样再输入加菲猫和米老鼠的文本后
模型就能顺利输出加菲猫和米老鼠的内容
因为LAURA在模型推理时
只需要把自己的参数矩阵恢复为原模型同款尺寸后叠加到原模型上
所以LOL模型的使用是完全不影响原模型的推理性能的
无论叠加多少个LARA上去都是一样的快
通过这样的设计
LARA就成功地拥有了低训练计算量需求
加超小体积加灵活即插即用的优点
记得保持关注之后还会继续更新
可视化无门槛理解AIGC基石模型原理的视频
